上下文并行(CP)#
TL;DR PCP 通过序列切分加速预填充。DCP 消除 KV 缓存冗余。
开发过程中的主要讨论请参考 RFC 以及该 RFC 引用或引用该 RFC 的相关链接。
什么是 CP?#
上下文并行(Context Parallel,CP) 是一种在多个设备上沿序列维度进行并行计算的策略。
预填充上下文并行(Prefill Context Parallel,PCP) 扩展了设备的世界规模,并使用专用的通信域。其主要目标是在预填充阶段对序列维度进行切分,使不同设备能够同时计算序列的不同块。KV 缓存沿序列维度分片存储到不同设备上。这种方法在不同程度上影响了预填充和解码阶段的计算逻辑。
解码上下文并行(Decode Context Parallel,DCP) 复用张量并行(TP)的通信域,不需要额外的设备。其主要目标是通过将 KV 缓存沿序列维度分片到 TP 域内的设备上(原本会存储冗余副本),消除 KV 缓存的重复存储。DCP 主要影响解码逻辑,以及分块预填充和缓存预填充的逻辑。
如何使用 CP?#
详细信息请参阅上下文并行用户指南。
工作原理是什么?#
设备分布#
我们为 PCP 引入了新的通信域,并为 DCP 复用了 TP。以下是 PCP2、DCP2 和 TP4 的新的设备布局。
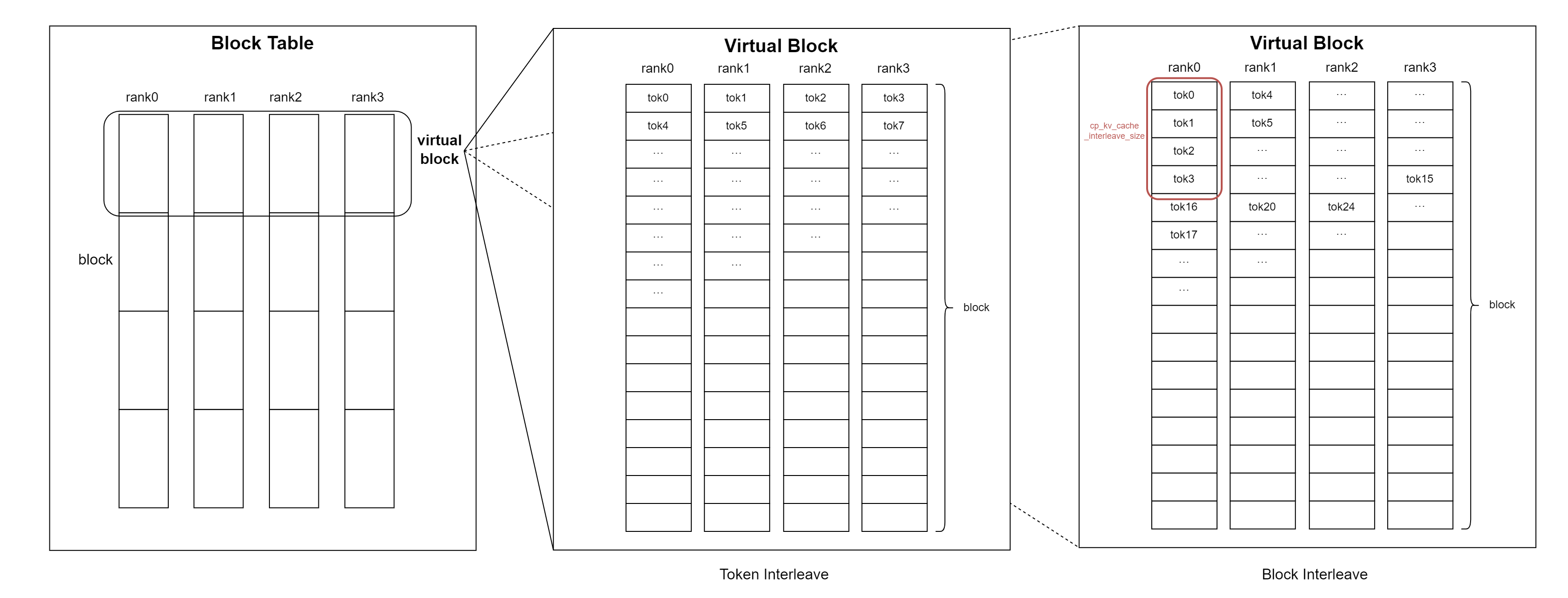
块表#
CP 对 KV 缓存存储进行序列分片。为了实现高效的存储和访问,token 以交错方式存储到各个设备上,交错粒度由 cp_kv_cache_interleave_size 决定,默认值为 cp_kv_cache_interleave_size=1,即“token 交错”。
鉴于 PCP 和 DCP 在 KV 缓存分片方面行为相似,我们将它们统称为 CP。具体地,cp_size = pcp_size * dcp_size,cp_rank = pcp_rank * dcp_size + dcp_rank。
如图所示,在块表中定义了一个虚拟块,同一 CP 设备组内的块构成一个虚拟块。虚拟块大小为 virtual_block_size = block_size * cp_size。
对于任意 token x,参考下图,其(虚拟)块索引为 x // virtual_block_size,虚拟块内的偏移量为 offset_within_virtual_block = x % virtual_block_size。本地块索引为 local_block_index = offset_within_virtual_block // cp_kv_cache_interleave_size,设备编号为 target_rank = local_block_index % cp_size。本地块内的偏移量为 (local_block_index // cp_size) * cp_kv_cache_interleave_size + offset_within_virtual_block % cp_kv_cache_interleave_size。
基于上述逻辑,调整了 slot_mapping 的计算过程,并修改了每个设备上的 slot_mapping 值,以确保 KV 缓存按预期沿序列维度分片并存储到不同设备上。
当前实现要求 block_size % cp_kv_cache_interleave_size == 0。
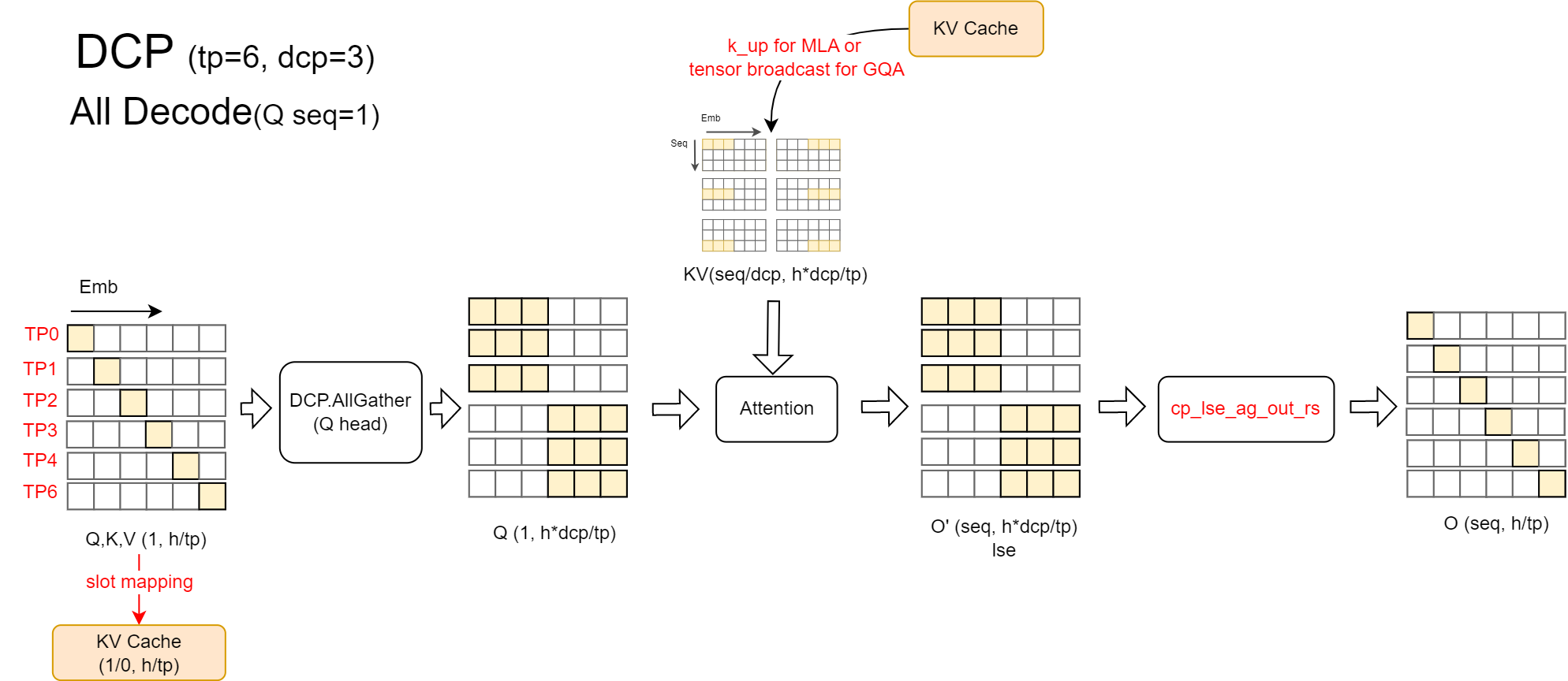
解码上下文并行(DCP)#
如上所述,DCP 的主要功能是将 KV 缓存沿序列维度分片存储。其影响体现在解码和分块预填充阶段的逻辑中。
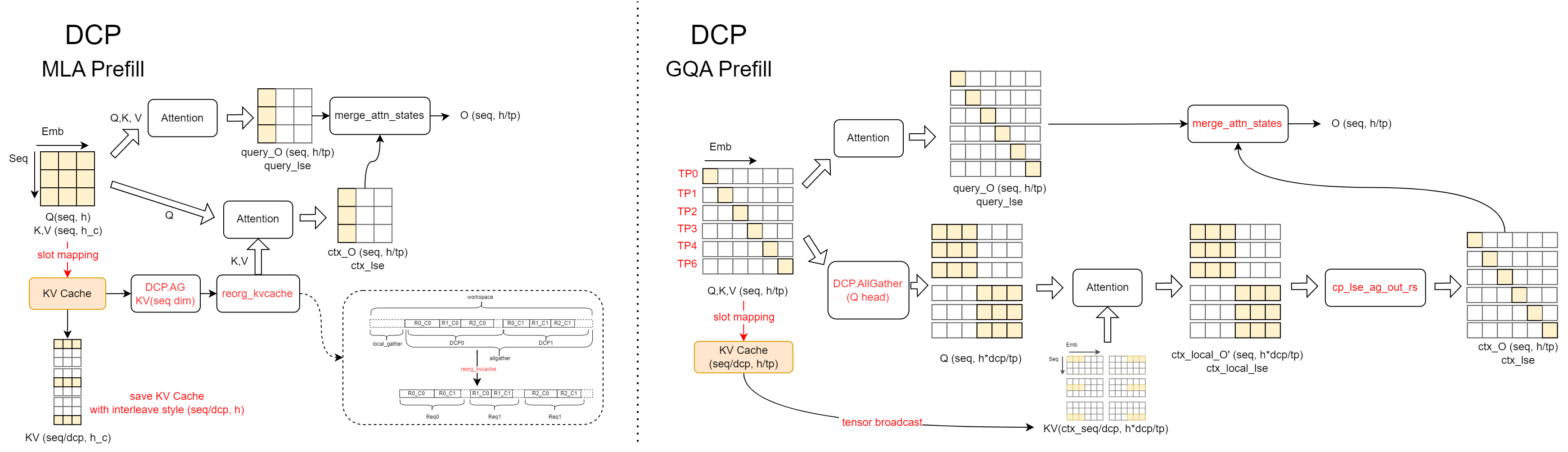
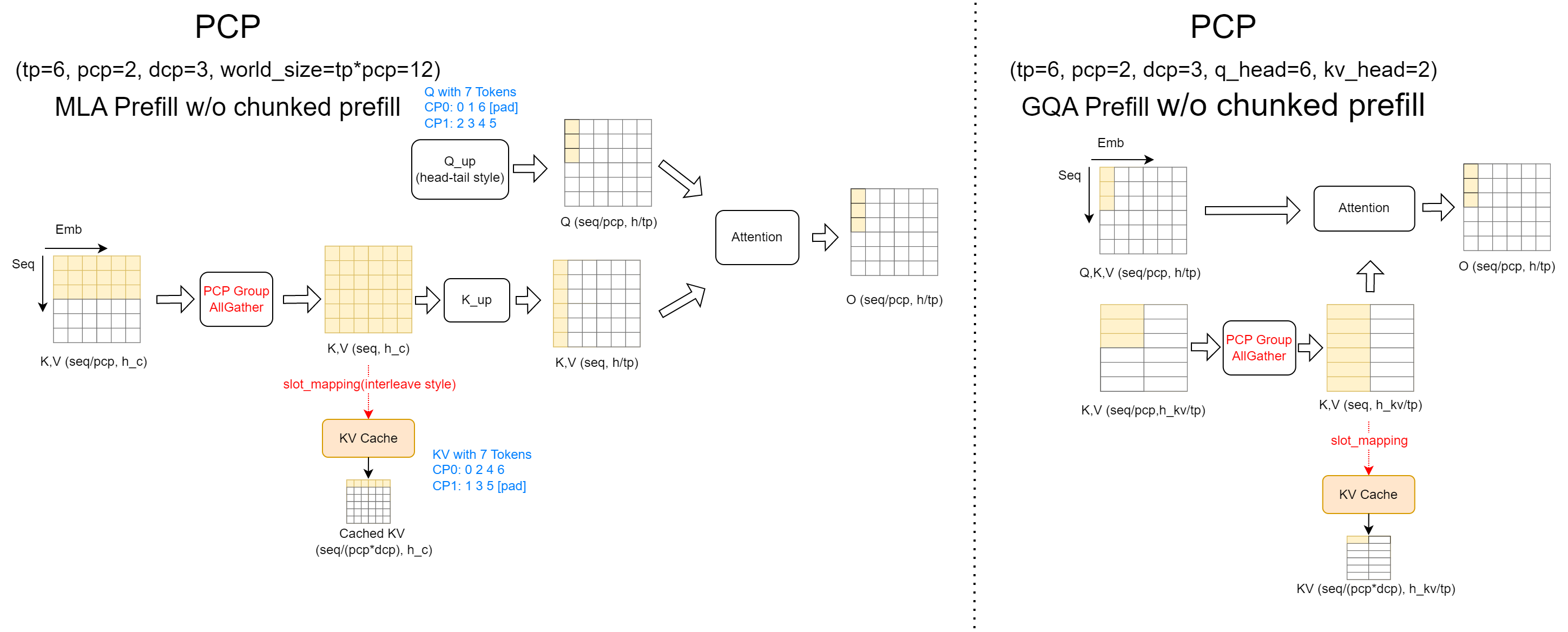
预填充阶段: 如图所示,在分块预填充计算过程中,MLA 和 GQA 后端采用了两种不同的逻辑实现。
在 MLA 后端,执行上下文 KV 缓存的
all_gather操作以聚合完整的 KV 值。然后,将这些 KV 值与当前块的 Q 值一起用于注意力计算。注意,在多请求场景下,直接聚合的 KV 结果会在请求之间交错。reorg_kvcache函数用于重组 KV 缓存,确保同一请求的 KV 缓存连续存储。在 GQA 后端,沿头维度对 Q 执行
all_gather。这是因为 DCP 与 TP 通信域重叠,且 DCP 组内的 Q 头各不相同。然而,它们需要与本地计算的 KV 缓存交换结果以进行在线 Softmax 更新。为确保结果更新时的正确性,通过头维度的all_gather在 DCP 组内同步 Q 值。在结果更新过程中,调用cp_lse_ag_out_rs聚合attn_output和attn_lse,更新结果,并对输出执行 reduce-scatter 操作。或者,也可以使用 all-to-all 通信交换输出和 LSE 结果,然后直接进行本地更新。这种方法与为兼容 PCP 而适配的逻辑一致。
解码阶段: 解码阶段的逻辑与 GQA 的分块预填充一致:首先沿 Q 头维度执行 all-gather 操作,以确保 DCP 组内的一致性。使用本地 KV 缓存计算结果后,通过 cp_lse_ag_out_rs 函数更新结果。
预填充上下文并行(PCP)#
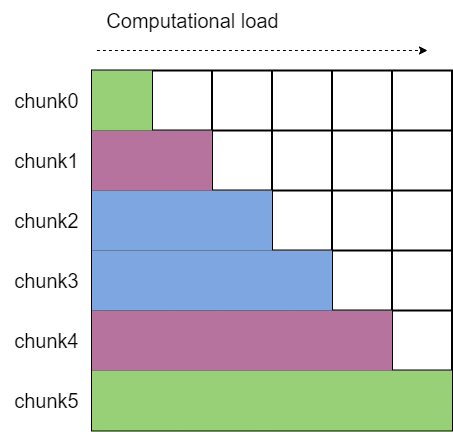
首尾风格的 Token 切分
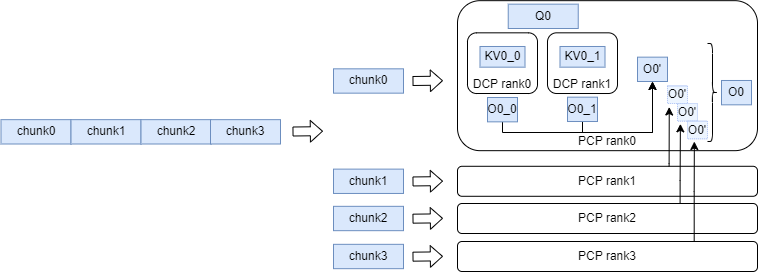
PCP 需要在预填充阶段切分输入序列,并确保各设备间的计算负载均衡。我们采用首尾风格进行切分与拼接:具体地,首先将序列填充到长度为 2*pcp_size,然后等分为 2*pcp_size 份。第一部分与最后一部分合并,第二部分与倒数第二部分合并,依此类推,从而为每个设备分配计算负载均衡的块。此外,由于 KV 或 Q 的 allgather 聚合会导致来自不同请求的块交错,我们计算 pcp_allgather_restore_idx 以快速恢复原始顺序。
这些逻辑在函数 _update_tokens_for_pcp 中实现。
预填充阶段:
在预填充阶段(不包括分块预填充),我们采用 all-gather KV 方法来解决单个 GPU 上序列不完整的问题。需要注意的是,我们每次只聚合当前层的 KV 值,使用后立即丢弃,避免了过高的峰值内存使用。该方法也可以直接应用于 KV 缓存存储(由于 KV 缓存切分方式与 PCP 序列切分不同,每个 GPU 不可避免地需要完整的 KV 值副本)。所有注意力后端在此逻辑上保持一致。
注意:虽然 Ring Attention 方法也可以以更低的峰值内存实现信息交换并支持计算-通信重叠,但经过评估,我们认为其开发复杂度较高且重叠收益有限,因此优先采用了 all-gather KV 实现。
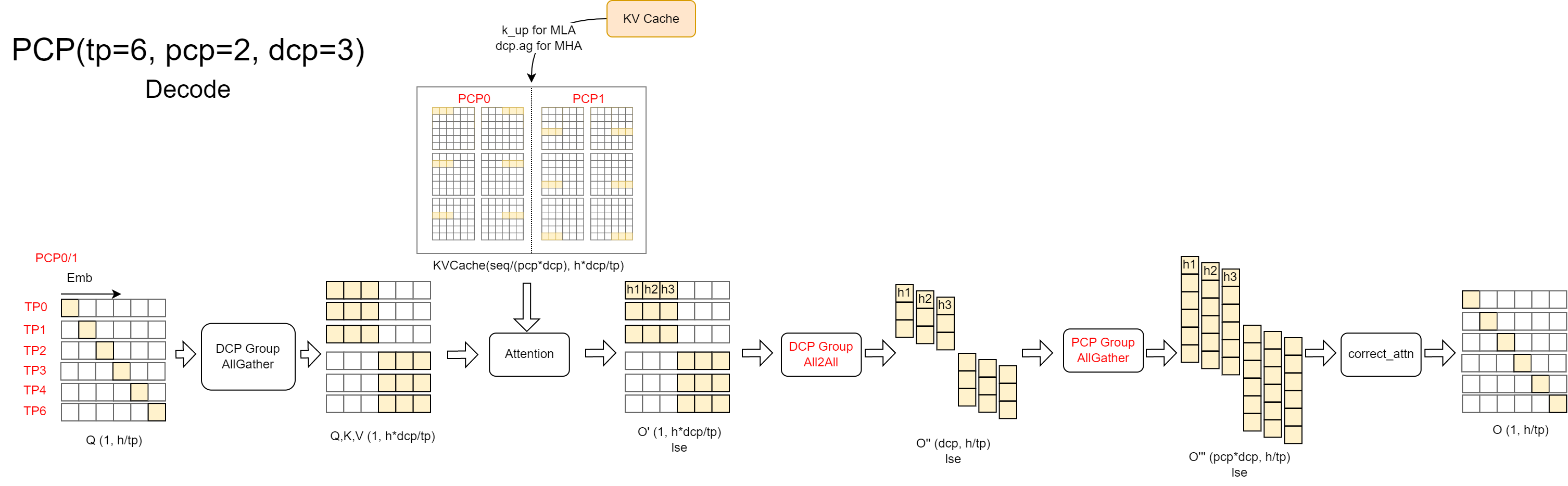
解码阶段:
在解码阶段,我们只需在 DCP all-to-all 通信交换输出和 LSE 之后、进行输出更新之前,在 PCP 组内添加一个 allgather 操作。
分块预填充:
目前,分块预填充的兼容性有三种可行方案:AllGatherQ、AllGatherKV 和 Ring-Attn。由于 PCP 对查询序列和 KV 缓存都进行了序列分片,我们需要确保其中一方拥有完整信息,或采用 Ring-Attn 等方法进行顺序计算。Ring-Attn 的优缺点在此不再赘述。
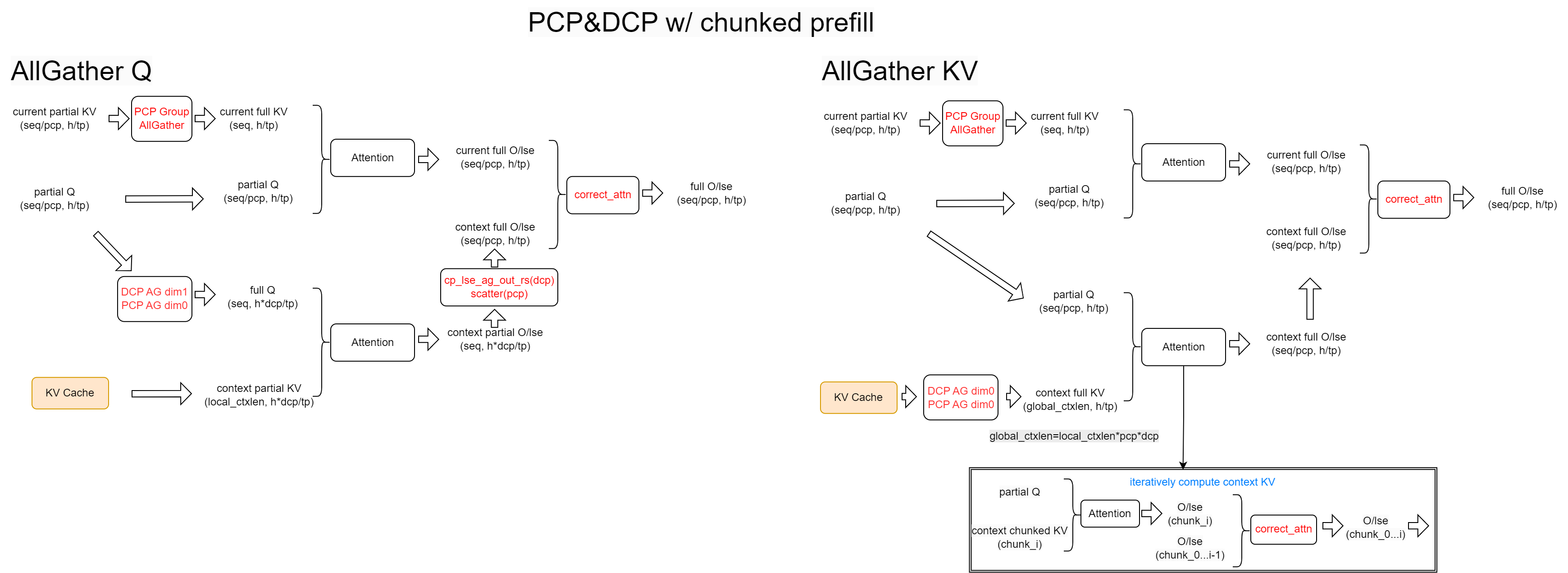
我们在 GQA 注意力后端实现了 AllGatherQ 方案,在 MLA 注意力后端实现了 AllGatherKV 方案。AllGatherQ 之后的工作流与解码阶段相同,而 AllGatherKV 之后的工作流与标准预填充阶段相同。详情请参考下图,具体步骤不再重复。
一个重要注意事项:当上下文长度过长时,AllGatherKV 可能导致显著的峰值内存使用。为了解决这个问题,我们采用了分段处理策略。通过预定义每轮处理的最大 KV 缓存量,我们依次完成每个段的注意力计算和在线 softmax 更新。