DFlash
DFlash is a speculative decoding method that uses a small diffusion-LLM draft model to predict an entire block of tokens in a single forward pass, conditioned on hidden states from the target model. Unlike Eagle-3's autoregressive drafting, DFlash uses a non-causal attention mask so that each query attends to both the verifier's hidden states and mask token embeddings simultaneously, producing all draft tokens at once. This block-parallel approach can yield 2--3x larger speedups than Eagle-3 on synchronous requests. The draft model uses Qwen3-style transformer layers but can be paired with any supported verifier.
How It Works
Architecture
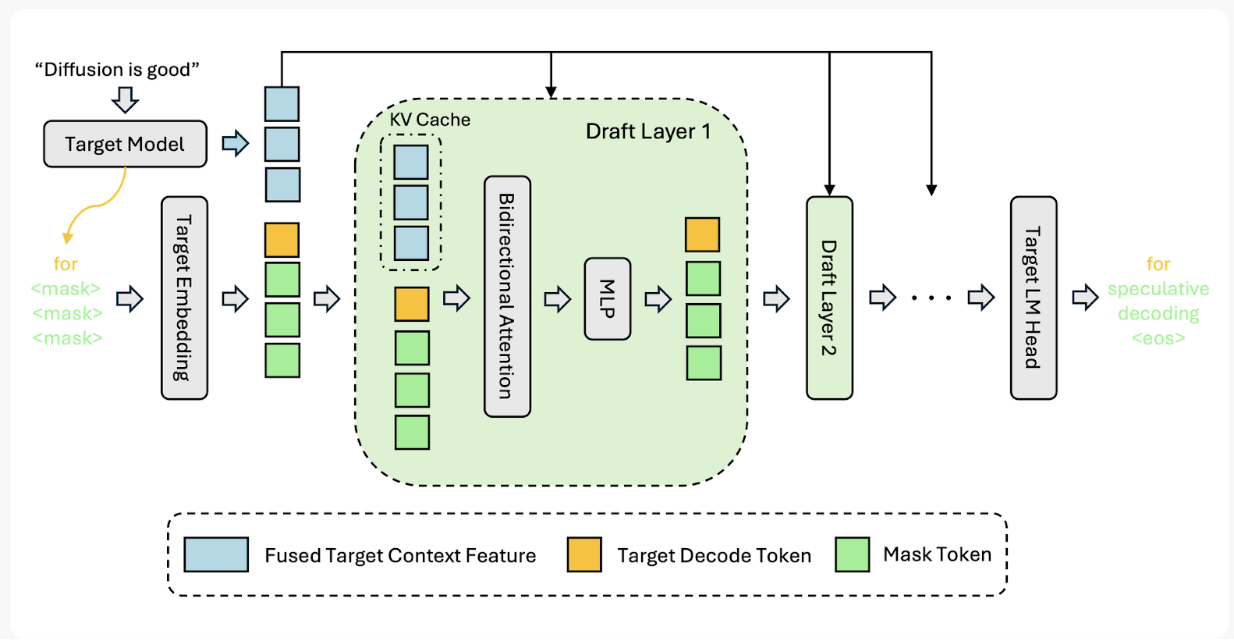
The target model produces hidden states (fused target context features) and decode tokens from the input sequence. These are combined with mask token embeddings and fed through a stack of draft layers, each consisting of bidirectional attention (with KV cache) and an MLP. The draft layers process context features and mask tokens together in a single forward pass. The output is projected through the target LM head to produce vocabulary logits for speculative decoding.
Anchor Point Mechanism
- Select anchors: Choose positions in the sequence
- Predict from anchors: Generate a block of tokens from each anchor in a single forward pass
- Verify blocks: Target model verifies the predicted blocks
- Accept valid tokens: Use the longest valid prefix
Pretrained Models
Pretrained DFlash speculator models are available on HuggingFace from the RedHatAI speculator models collection:
| Verifier | Speculator |
|---|---|
google/gemma-4-31B-it | RedHatAI/gemma-4-31B-it-speculator.dflash |
Note: DFlash is under active development. Not all hardware configurations have been validated yet — refer to individual model cards for details.
Research & Citation
DFlash is based on research from Z Lab: DFlash Project Page | arXiv Paper
@article{chen2026dflash,
title={DFlash: Block Diffusion for Flash Speculative Decoding},
author={Chen, Jian and Liang, Yesheng and Liu, Zhijian},
journal={arXiv preprint arXiv:2602.06036},
year={2026}
}
See Also
- Train DFlash Tutorial -- Step-by-step training guide