Eagle-3
Eagle-3 is a speculative decoding algorithm that uses a lightweight draft model to autoregressively predict multiple tokens ahead, which are then verified by the target model in a single forward pass. The draft model uses Llama-style transformer layers and is trained to minimize KL divergence against the target model's logits. It supports cross-tokenizer vocabularies and can be paired with any supported verifier model.
How It Works
Architecture
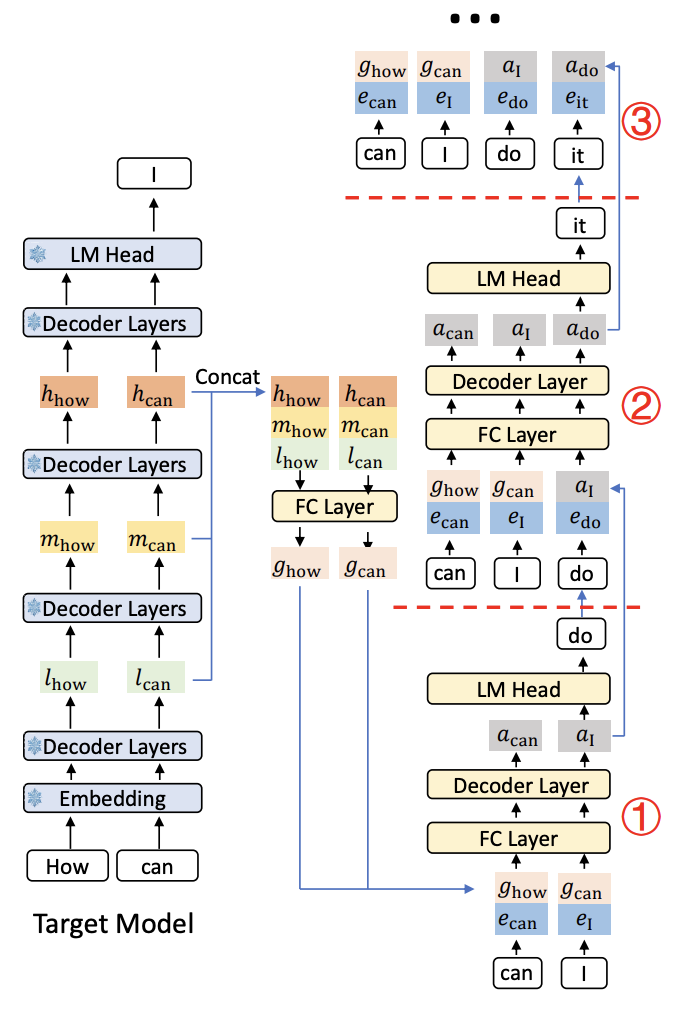
The target model produces hidden states at selected layers, which are concatenated and projected through an FC layer alongside token embeddings. These pass through Llama-style decoder layers (default: 1) and an LM head to produce draft logits. At each autoregressive step, the draft model takes the previous token's embedding and hidden states to predict the next token.
Inference Process
- Eagle-3 autoregressively drafts K tokens, each step feeding the previous prediction back through the draft model
- Target model verifies all K draft tokens in one forward pass
- The longest correct prefix is accepted
- Repeat from the last accepted token
Pretrained Models
Pretrained Eagle-3 speculator models trained by our team are available on HuggingFace from the RedHatAI speculator models collection. Below are a few examples of models we've produced:
| Verifier | Speculator |
|---|---|
Qwen/Qwen3-8B | RedHatAI/Qwen3-8B-speculator.eagle3 |
meta-llama/Llama-4-Maverick-17B-128E-Instruct | RedHatAI/Llama-4-Maverick-17B-128E-Instruct-speculator.eagle3 |
openai/gpt-oss-20b | RedHatAI/gpt-oss-20b-speculator.eagle3 |
google/gemma-4-31B-it | RedHatAI/gemma-4-31B-it-speculator.eagle3 |
Research & Citation
Eagle-3 is based on research from SafeAI Lab: EAGLE Repository | arXiv Paper
@article{li2024eagle,
title={EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty},
author={Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang},
journal={arXiv preprint arXiv:2401.15077},
year={2024}
}
See Also
- Train Eagle-3 Online -- Online training tutorial
- Train Eagle-3 Offline -- Offline training tutorial