Adding a Diffusion Model¶
This guide walks you through adding a new diffusion model to vLLM-Omni. We use Qwen-Image as the primary example, with references to other models (LongCat, Flux, Wan2.2) to illustrate different patterns.
Table of Contents¶
- Overview
- Directory Structure
- Basic Implementation
- Advanced Features
- Troubleshooting
- Pull Request Checklist
- Reference Implementations
- Summary
Overview¶
vLLM-Omni's diffusion inference follows this architecture:
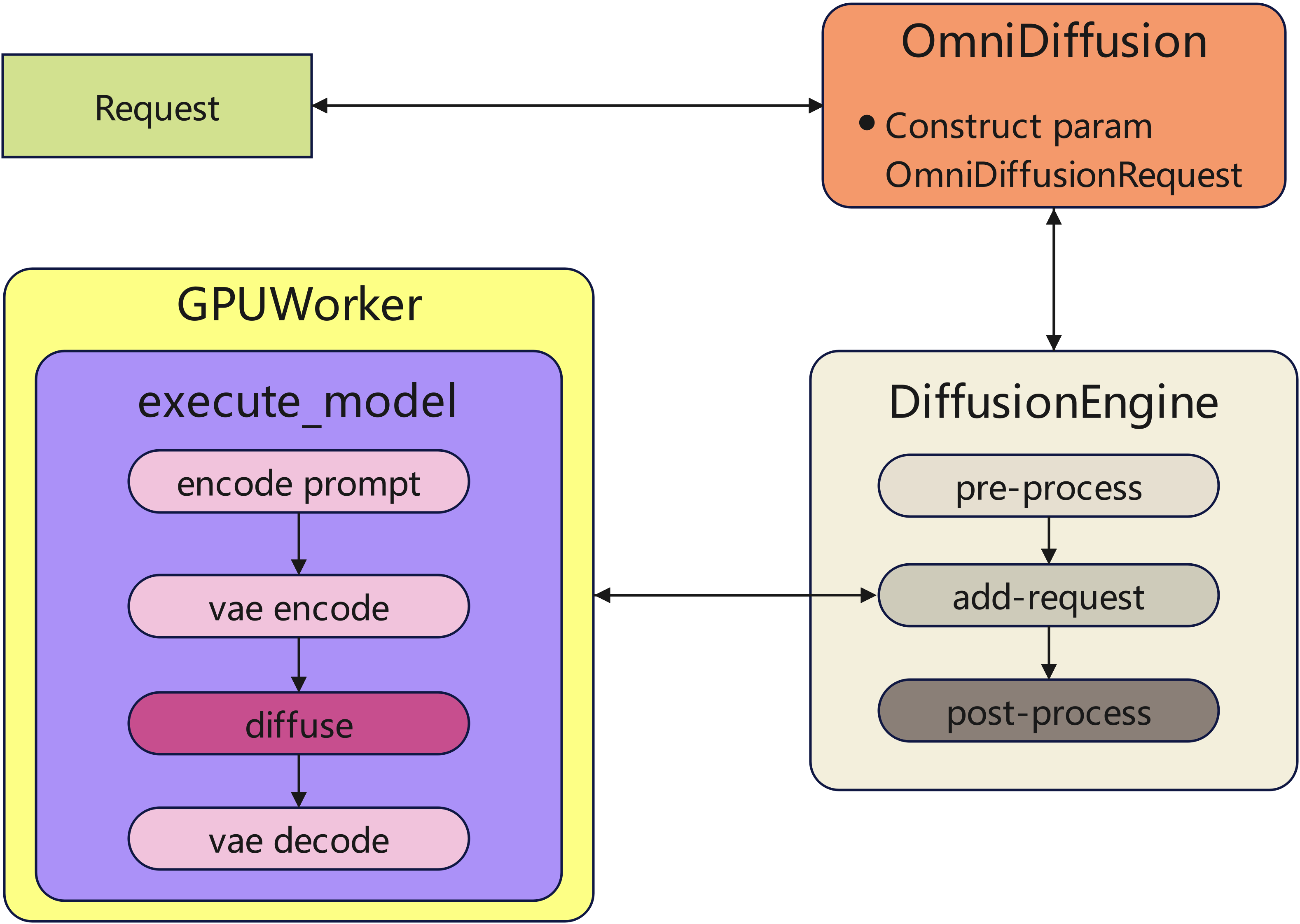
Key Components:
- Request Handling: User prompts →
OmniDiffusionRequest - Diffusion Engine: Request → Preprocessing (Optional) → Pipeline execution -> Post-processing
- Pipeline Execution: Request → Encode prompt → Diffusion steps → Vae decode
Directory Structure¶
Organize your model files following this structure:
vllm_omni/
└── diffusion/
├── registry.py # ← Register your model here
├── request.py # Request data structures
└── models/
└── your_model_name/ # ← Create this directory
├── __init__.py # Export pipeline and transformer
├── pipeline_xxx.py # Pipeline implementation
└── xxx_transformer.py # Transformer implementation
Naming Conventions:
- Model directory:
your_model_name(lowercase, underscores), e.g.,qwen_image,flux,longcat_image,wan2_2 - Pipeline file:
pipeline_xxx.pywherexxxdescribes the task, e.g.,pipeline_qwen_image.py,pipeline_qwen_image_edit.py - Transformer file:
xxx_transformer.pymatching transformer class name, e.g.,qwen_image_transformer.py,flux_transformer.py
Basic Implementation¶
This section covers the minimal steps to get a model working in vLLM-Omni with basic features (online/offline serving, batch requests).
Step 1: Adapt Transformer Model¶
The transformer is the core denoising network. Start by copying the transformer implementation from Diffusers and making these adaptations.
1.1: Remove Diffusers Mixins¶
Diffusers' Mixin classes are not needed in vLLM-Omni. Remove them:
# Before (Diffusers)
- from diffusers.models.modeling_utils import ModelMixin
- from diffusers.models.attention_processor import AttentionModuleMixin
- class YourModelTransformer2DModel(ModelMixin, AttentionModuleMixin):
+ class YourModelTransformer2DModel(nn.Module):
"""Your transformer model."""
Example mixins to remove:
ModelMixin- Weight loading utilities (vLLM-Omni has its own weight loader)AttentionModuleMixin- Attention processors (using vLLM-Omni's Attention layer instead)ConfigMixin- Config management (not needed)PeftAdapterMixin- Parameter efficient finetune utilities (not needed)
1.2: Replace Attention Implementation¶
The most important adaptation: Replace Diffusers' attention with vLLM-Omni's optimized Attention layer.
Before (Diffusers):
from diffusers.models.attention_processor import dispatch_attention_fn
class YourAttentionBlock(nn.Module):
def forward(self, hidden_states, encoder_hidden_states=None, ...):
...
hidden_states = dispatch_attention_fn(
query, key, value,
attn_mask=attention_mask,
dropout_p=0.0,
is_causal=False,
backend=self._attention_backend,
)
After (vLLM-Omni):
from vllm_omni.diffusion.attention.layer import Attention
from vllm_omni.diffusion.attention.backends.abstract import AttentionMetadata
class YourSelfAttentionBlock(nn.Module):
def __init__(self, ...):
super().__init__()
# Initialize vLLM-Omni's Attention layer.
# `role` lets users target this site with --diffusion-attention-config
# (e.g. --diffusion-attention-config.per_role.self.backend SAGE_ATTN).
self.attn = Attention(
num_heads=self.num_heads,
head_size=self.head_dim,
softmax_scale=1.0 / (self.head_dim ** 0.5),
causal=False, # Diffusion models typically use bidirectional attention
num_kv_heads=self.num_kv_heads,
role="self",
)
def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, ...):
...
# Create attention metadata
attn_metadata = AttentionMetadata(attn_mask=attention_mask)
hidden_states = self.attn(query, key, value, attn_metadata=attn_metadata)
Key Points:
- Attention layer initialization: Done in
__init__, not per-forward - Tensor shapes: vLLM-Omni
Attentionexpects QKV to have[B, seq, num_heads, head_dim]shape - AttentionMetadata: Wraps attention mask and other metadata
- Role: Tag every
Attentionsite with arolestring so users can configure backends per role (see below)
Declaring attention roles
The role argument is a free-form string that identifies this attention site. Users can match it from --diffusion-attention-config.per_role.<role>.* to swap backends without touching model code. Two conventions cover the common cases:
| Convention | When to use | Example |
|---|---|---|
"self" | Q/K/V come from the same hidden state | DiT self-attention block |
"cross" | K/V come from a separate encoder_hidden_states | Text-conditioned cross-attention |
For multi-modal or unusual sites, use a dot-namespaced role and pair it with role_category so it can fall back to the generic config when nothing model-specific is set:
# A model-specific cross-attention site that user config can target
# either as 'mymodel.audio_to_video' (exact) or as 'cross' (category fallback).
self.audio_to_video_attn = Attention(
num_heads=self.num_heads,
head_size=self.head_dim,
softmax_scale=1.0 / (self.head_dim ** 0.5),
causal=False,
role="mymodel.audio_to_video",
role_category="cross",
)
For cross-attention sites whose K/V are replicated across ranks (e.g. text encoder output), pass skip_sequence_parallel=True to opt this layer out of sequence-parallel sharding.
Attention backends: When the user does not configure a backend, vLLM-Omni asks the current platform for its default (typically FLASH_ATTN on CUDA when available). Users override the default via --diffusion-attention-backend, the DIFFUSION_ATTENTION_BACKEND env var, or finer-grained --diffusion-attention-config.per_role.* flags. See Diffusion Attention Backends for the full configuration surface.
1.3: Replace Imports and Utilities¶
Logger:
- from diffusers.utils import logging
- logger = logging.get_logger(__name__)
+ from vllm.logger import init_logger
+ logger = init_logger(__name__)
Custom layers from vLLM and vLLM-Omni (if needed):
from vllm.model_executor.layers.layernorm import RMSNorm
from vllm_omni.diffusion.layers.rope import RotaryEmbedding
from vllm_omni.diffusion.layers.adalayernorm import AdaLayerNorm
1.4: Remove Training-Only Code¶
Remove code that's only needed for training:
# Remove gradient checkpointing
- if torch.is_grad_enabled() and self.gradient_checkpointing:
- hidden_states = torch.utils.checkpoint.checkpoint(
- self._forward_block, hidden_states, ...
- )
- else:
- hidden_states = self._forward_block(hidden_states, ...)
+ hidden_states = self._forward_block(hidden_states, ...)
# Remove training-specific attributes
- self.gradient_checkpointing = False
# Remove dropout (set to 0 or remove)
- self.dropout = nn.Dropout(dropout_prob)
+ # Removed dropout for inference
1.5: Add Configuration Support¶
Add support for vLLM-Omni's OmniDiffusionConfig:
from vllm_omni.diffusion.data import OmniDiffusionConfig
class YourModelTransformer2DModel(nn.Module):
def __init__(
self,
*,
od_config: OmniDiffusionConfig | None = None, # ← Add vLLM-Omni config
# ... other model-specific parameters
num_layers: int = 28,
hidden_size: int = 3072,
num_heads: int = 24,
**kwargs,
):
super().__init__()
# Store config
self.od_config = od_config
self.parallel_config = od_config.parallel_config if od_config else None
# Model architecture
self.num_layers = num_layers
self.hidden_size = hidden_size
# ... initialize layers
Step 2: Adapt Pipeline¶
The pipeline orchestrates the full generation process (text encoding, denoising loop, VAE decoding). Adapt it from Diffusers format to vLLM-Omni's interface.
2.1: Remove Diffusers Inheritance¶
Remove Diffusers base classes:
- from diffusers import DiffusionPipeline
- from diffusers.loaders import LoraLoaderMixin
- class YourModelPipeline(DiffusionPipeline, LoraLoaderMixin):
+ class YourModelPipeline(nn.Module):
"""Your model pipeline for vLLM-Omni."""
2.2: Adapt __init__ Method¶
Before (Diffusers):
class YourModelPipeline(DiffusionPipeline):
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
transformer: YourTransformer,
scheduler: FlowMatchScheduler,
):
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
transformer=transformer,
scheduler=scheduler,
)
After (vLLM-Omni):
import os
from diffusers import AutoencoderKL
from diffusers.schedulers import FlowMatchEulerDiscreteScheduler
from transformers import CLIPTextModel, CLIPTokenizer
from vllm_omni.diffusion.data import OmniDiffusionConfig
from vllm_omni.diffusion.distributed.utils import get_local_device
from vllm_omni.diffusion.utils.tf_utils import get_transformer_config_kwargs
from vllm_omni.diffusion.models.your_model_name.your_model_transformer import (
YourModelTransformer2DModel,
)
class YourModelPipeline(nn.Module):
def __init__(
self,
*,
od_config: OmniDiffusionConfig,
prefix: str = "",
):
super().__init__()
self.od_config = od_config
self.parallel_config = od_config.parallel_config
self.device = get_local_device()
model = od_config.model
local_files_only = os.path.exists(model)
# Load components from checkpoint
self.scheduler = FlowMatchEulerDiscreteScheduler.from_pretrained(
model, subfolder="scheduler", local_files_only=local_files_only)
self.text_encoder = CLIPTextModel.from_pretrained(
model, subfolder="text_encoder", local_files_only=local_files_only).to(self.device)
self.tokenizer = CLIPTokenizer.from_pretrained(
model, subfolder="tokenizer", local_files_only=local_files_only)
self.vae = AutoencoderKL.from_pretrained(
model, subfolder="vae", local_files_only=local_files_only).to(self.device)
# Initialize transformer with vLLM-Omni config
transformer_kwargs = get_transformer_config_kwargs(
od_config.tf_model_config, YourModelTransformer2DModel)
self.transformer = YourModelTransformer2DModel(
od_config=od_config, **transformer_kwargs)
# Store VAE scale factor for latent space conversions
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.default_sample_size = 128 # Default latent size
Key Changes:
od_configparameter: All configuration throughOmniDiffusionConfig- Manual component loading: No
register_modules(), load each component explicitly - Local files support: Check
os.path.exists(model)for local checkpoints - Transformer with config: Pass
od_configto transformer constructor
2.3: Adapt __call__ → forward Method¶
Change signature:
- @torch.no_grad()
- def __call__(
+ def forward(
self,
+ req: DiffusionRequestBatch, # ← Add request-batch parameter here
- ):
+ ) -> list[DiffusionOutput]: # ← Add return type
OmniDiffusionRequest is a dataclass that contains one prompt and the sampling parameters OmniDiffusionSamplingParams for one logical diffusion request. It also contains a request_id for other components to trace this request and its outputs. Before pipeline execution, the runner wraps one or more independent requests into DiffusionRequestBatch.
DiffusionRequestBatch exposes compatibility properties such as prompts, sampling_params, and request_id. Pipelines that can execute the whole request batch in one forward pass should set supports_request_batch = True; other pipelines still receive a single-request batch and return a one-element output list.
See some parameters in OmniDiffusionSamplingParams as follows:
| parameters | type | value | function |
|---|---|---|---|
num_inference_steps | int | 50 | The number of diffusion steps during inference |
guidance_scale | float | 0.0 | The classifier free guidance scale |
width and height | int | None | The width and height of the generated image |
Extract parameters from request:
from vllm_omni.diffusion.data import DiffusionOutput
from vllm_omni.diffusion.worker.request_batch import DiffusionRequestBatch
def forward(
self,
req: DiffusionRequestBatch,
) -> list[DiffusionOutput]:
# Extract prompts from the request batch
prompts = [
p if isinstance(p, str) else (p.get("prompt") or "")
for p in req.prompts
]
# Extract common sampling parameters
sampling_params = req.sampling_params
num_inference_steps = sampling_params.num_inference_steps or 50
guidance_scale = sampling_params.guidance_scale or 7.5
height = sampling_params.height or (self.default_sample_size * self.vae_scale_factor)
width = sampling_params.width or (self.default_sample_size * self.vae_scale_factor)
# For image editing pipelines, extract media from each prompt dict
input_images = []
for p in req.prompts:
multi_modal_data = p.get("multi_modal_data", {}) if isinstance(p, dict) else {}
input_images.append(multi_modal_data.get("image"))
# ... rest of generation logic
For an image editing model, the request prompt can be a dict like:
Wrap output:
# Generate images
images = self.vae.decode(latents)[0]
- return {"images": images}
+ return DiffusionOutput(output=images)
2.4: Extract Pre/Post-Processing Functions¶
vLLM-Omni separates image processing from the main pipeline for better modularity.
Post-processing function (required):
def get_your_model_post_process_func(
od_config: OmniDiffusionConfig,
):
"""
Create post-processing function for your model.
Returns a function that converts latents to images.
"""
from diffusers.image_processor import VaeImageProcessor
import json
# Load VAE config to get scale factor
model_path = od_config.model
if not os.path.exists(model_path):
from vllm_omni.diffusion.model_loader.utils import download_weights_from_hf_specific
model_path = download_weights_from_hf_specific(model_path, None, ["*"])
vae_config_path = os.path.join(model_path, "vae/config.json")
with open(vae_config_path) as f:
vae_config = json.load(f)
vae_scale_factor = 2 ** (len(vae_config["block_out_channels"]) - 1)
# Create image processor
image_processor = VaeImageProcessor(vae_scale_factor=vae_scale_factor)
def post_process_func(images: torch.Tensor):
return image_processor.postprocess(images, output_type="pil")
return post_process_func
Pre-processing function (for image editing pipelines):
def get_your_model_pre_process_func(
od_config: OmniDiffusionConfig,
):
"""
Create pre-processing function for image editing.
Returns a function that prepares input images.
"""
from PIL import Image
from diffusers.image_processor import VaeImageProcessor
# Load VAE config
# ... (similar to post_process_func)
image_processor = VaeImageProcessor(vae_scale_factor=vae_scale_factor)
def pre_process_func(
request: OmniDiffusionRequest,
):
prompt = request.prompt
multi_modal_data = prompt.get("multi_modal_data", {}) if not isinstance(prompt, str) else None
raw_image = multi_modal_data.get("image", None) if multi_modal_data is not None else None
# image pre-processing
# after pre-processing, update the request attributes
...
return request
return pre_process_func
2.5: Add Weight Loading Support¶
Add methods for automatic weight downloading and loading:
from vllm_omni.diffusion.model_loader.diffusers_loader import DiffusersPipelineLoader
from vllm.model_executor.models.utils import AutoWeightsLoader
class YourModelPipeline(nn.Module):
def __init__(self, *, od_config: OmniDiffusionConfig, prefix: str = ""):
super().__init__()
# ... initialization code
# Define weight sources for automatic loading
self.weights_sources = [
DiffusersPipelineLoader.ComponentSource(
model_or_path=od_config.model,
subfolder="transformer",
revision=None,
prefix="transformer.",
fall_back_to_pt=True,
)
]
def load_weights(self, weights: Iterable[tuple[str, torch.Tensor]]) -> set[str]:
"""
Customize the weight loading behavior, such as filter weights name.
Args:
weights: Iterable of (param_name, param_tensor) tuples
Returns:
Set of loaded parameter names
"""
loader = AutoWeightsLoader(self)
return loader.load_weights(weights)
Step 3: Register Model¶
Register your model in vllm_omni/diffusion/registry.py so vLLM-Omni can discover and load it.
3.1: Register Pipeline Class¶
# vllm_omni/diffusion/registry.py
_DIFFUSION_MODELS = {
# Format: "PipelineClassName": (module_folder, module_file, class_name)
# Existing models
"QwenImagePipeline": ("qwen_image", "pipeline_qwen_image", "QwenImagePipeline"),
"FluxPipeline": ("flux", "pipeline_flux", "FluxPipeline"),
# Add your model
"YourModelPipeline": (
"your_model_name", # Module folder name
"pipeline_your_model", # Python file name (without .py)
"YourModelPipeline", # Pipeline class name
),
}
3.2: Register Pre/Post-Processing Function¶
# vllm_omni/diffusion/registry.py
_DIFFUSION_PRE_PROCESS_FUNCS = {
# arch: pre_process_func
# `pre_process_func` function must be placed in {mod_folder}/{mod_relname}.py,
# where mod_folder and mod_relname are defined and mapped using `_DIFFUSION_MODELS` via the `arch` key
"GlmImagePipeline": "get_glm_image_pre_process_func",
"QwenImageEditPipeline": "get_qwen_image_edit_pre_process_func",
# Add your model
"YourModelPipeline": "get_your_model_pre_process_func", # Optional
}
_DIFFUSION_POST_PROCESS_FUNCS = {
# Format: "PipelineClassName": "function_name"
# Existing models
"QwenImagePipeline": "get_qwen_image_post_process_func",
"FluxPipeline": "get_flux_post_process_func",
# Add your model
"YourModelPipeline": "get_your_model_post_process_func",
}
3.3: Export from Module¶
Create/update __init__.py to export your classes:
# vllm_omni/diffusion/models/your_model_name/__init__.py
from .pipeline_your_model import (
YourModelPipeline,
get_your_model_post_process_func,
)
from .your_model_transformer import YourModelTransformer2DModel
__all__ = [
"YourModelPipeline",
"YourModelTransformer2DModel",
"get_your_model_post_process_func",
]
Step 4: Add Example Script¶
If your model is one of Text-to-Image, Text-to-Audio, Text-to-Video, Image-to-Image, Image-to-Video models, you can simply try one of the following offline inference scripts to run your model:
| Model Category | Offline Inference Script |
|---|---|
| Image-to-Image | examples/offline_inference/image_to_image/image_edit.py |
| Image-to-Video | examples/offline_inference/image_to_video/image_to_video.py |
| Text-to-Image | examples/offline_inference/text_to_image/text_to_image.py |
| Text-to-Audio | examples/offline_inference/text_to_audio/text_to_audio.py |
| Text-to-Video | examples/offline_inference/text_to_video/text_to_video.py |
If new CLI arguments need to be added, please edit the offline inference script corresponding to your model category from the table above, and update the example inference script in its corresponding document file (e.g., examples/offline_inference/text_to_video/text_to_video.md).
For online inference, all the supported tasks are listed in docs/user_guide/examples/online_serving/. If your model falls into these categories, please check the corresponding documentation in this folder and the example at examples/online_serving/TASK_NAME. Update them accordingly if needed.
If your model is an Omni (understanding and generation) model, please follow the steps below.
4.1: Create Example File¶
Taking BAGEL model as examples for both offline and online:
- Offline:
examples/offline_inference/bagel/ - Online:
examples/online_serving/bagel/
Add two example folders for your model:
mkdir -p examples/offline_inference/your_model_name
mkdir -p examples/online_serving/your_model_name
Offline (recommended minimum): create examples/offline_inference/your_model_name/end2end.py and a README.
- Script:
examples/offline_inference/your_model_name/end2end.py - Parse args like BAGEL (
--model,--modality, optional--image-path,--steps, etc.) - Use
from vllm_omni.entrypoints.omni import Omni(orOmniDiffusionif your model is diffusion-only) - Save outputs (images/audio/video/text) with deterministic filenames (e.g.,
output_0_0.png) - Doc:
examples/offline_inference/your_model_name/README.md - Include at least one runnable command, e.g.:
cd examples/offline_inference/your_model_name
python end2end.py --model your-org/your-model-name --modality text2img --prompts "A cute cat"
4.2: Add Online Serving Example (OpenAI-Compatible)¶
Mirror BAGEL’s online serving setup:
- Server launcher:
examples/online_serving/your_model_name/run_server.sh - Wrap
vllm serve ... --omni --port ...(and--stage-configs-path ...if needed) - Client:
examples/online_serving/your_model_name/openai_chat_client.py - Send requests to
POST /v1/chat/completions - Support multimodal inputs (e.g., base64 image) if your model needs it
- Doc:
examples/online_serving/your_model_name/README.md - Include both “launch server” and “send request”:
# Terminal 1: launch server
cd examples/online_serving/your_model_name
bash run_server.sh
# Terminal 2: send request
python openai_chat_client.py --prompt "A cute cat" --modality text2img
Step 5: Test Your Implementation¶
Before submitting, thoroughly test your implementation.
5.1: Performance/Speed Check¶
Manually compare latency/throughput and output quality against a Diffusers baseline.
For a fair comparison, keep the same prompt, seed, resolution, num_inference_steps, and guidance settings, and run multiple trials to reduce randomness. Record the results (and your hardware / driver / CUDA versions) in your PR description.
5.2 Functionality Check in CI¶
To ensure project maintainability and sustainable development, please submit test code (unit tests, system tests, or end-to-end tests) alongside their code changes.
For comprehensive testing guidelines and the definition of test levels (L1-L5), please refer to the Multi-Level Automated Testing System Documentation. You are at least required to add an L4 functionality test described in that document.
Advanced Features¶
Once basic implementation works, add advanced features for better performance.
torch.compile Support¶
Enable automatic compilation for repeated blocks:
# In your_model_transformer.py
class YourModelTransformer2DModel(nn.Module):
# Specify which blocks can be compiled
_repeated_blocks = ["YourTransformerBlock"] # List of block class names
def __init__(self, ...):
super().__init__()
# ... initialization
vLLM-Omni automatically compiles blocks in _repeated_blocks when torch.compile is available.
Tensor Parallelism¶
See detailed guide: How to add Tensor Parallel support
Quick setup:
- Replace Linear layers by various parallel linear layers (e.g.,
ColumnParallelLinear) in vLLM - Check
tp_sizevalidity:hidden_dim,num_heads, andnum_kv_headsmust be divisible bytp_size
Usage: Set tensor_parallel_size when initializing:
CFG Parallelism¶
See detailed guide: How to add CFG-Parallel support
Quick setup:
- Implement
diffuse()method - Inherit
CFGParallelMixinin your pipeline class
Usage: Set cfg_parallel_size when initializing:
Sequence Parallelism¶
See detailed guide: How to add Sequence Parallel support
Quick setup:
- Add
_sp_planclass attribute to transformer - Specify where to shard/gather tensors
Usage: Set ulysses_degree and ring_degree when initializing:
Step Execution¶
See detailed design guide: How to add step execution support
Use this only when your pipeline can be split into stable request-scoped and step-scoped phases. The reference implementation is QwenImagePipeline, which maps its request-level forward() into:
prepare_encode()for prompt encoding, latent init, timestep prep, and per-request scheduler setup.denoise_step()for one transformer/noise prediction.step_scheduler()for one scheduler update andstep_indexadvance.post_decode()for the final VAE decode.
Do not enable step_execution=True until those four methods are implemented and validated against the request-level path.
If you want the pipeline to work with the experimental batched step-wise path (max_num_seqs > 1), also see: Continuous Batching for Step-Wise Diffusion.
If you expose this in example scripts or recipes, keep it opt-in. Surface runtime features like step_execution as optional flags instead of silently turning them on. For Qwen-Image-style serving examples, document --step-execution as the feature gate and --max-num-seqs N as the companion batching knob.
Cache Acceleration¶
TeaCache¶
See detailed guide: How to add TeaCache support
Quick setup:
- Write extractor function
- Register in
EXTRACTOR_REGISTRY - Add polynomial coefficients
Usage: Set cache_backend and cache_config when initializing:
Cache-DiT¶
See detailed guide: How to add Cache-DiT support
Quick setup:
- For standard models: Works automatically
- For complex architectures: Write custom cache config
Usage: Set cache_backend and cache_config when initializing:
omni = Omni(model="your-model",
cache_backend="cache_dit",
cache_config={
"Fn_compute_blocks": 1,
"Bn_compute_blocks": 0,
"max_warmup_steps": 4,
}
)
CPU Offload¶
See detailed guide: CPU Offloading for Diffusion Models
vLLM-Omni provides two offloading strategies to reduce GPU memory usage:
- Model-level offload: Mutual exclusion between DiT and encoders (only one on GPU at a time)
- Layerwise (Blockwise) offload: Keeps only a single transformer block on GPU at a time with compute-memory overlap
Usage: Enable offload when initializing:
# Model-level offload
omni = Omni(model="your-model", enable_cpu_offload=True)
# Layerwise offload
omni = Omni(model="your-model", enable_layerwise_offload=True)
To support layerwise offloading: Define the blocks attribute name in your transformer:
class WanTransformer3DModel(nn.Module):
_layerwise_offload_blocks_attrs = ["blocks"] # Attribute name containing transformer blocks
def __init__(self):
self.blocks = nn.ModuleList([...]) # Transformer blocks
Note: Layerwise offloading is primarily recommended for large video generation models where the compute cost per block is high enough to effectively overlap with memory prefetch operations.
Diffusion Pipeline Profiler (Performance Profiling)¶
When adapting a new diffusion model, it is often useful to analyze the latency of key components such as text encoding, diffusion denoising, and VAE decoding. vLLM-Omni provides a timing utility via DiffusionPipelineProfilerMixin to help developers quickly identify performance bottlenecks.
Info
DiffusionPipelineProfilerMixin is different from using torch.profiler for diffusion models, as introduced in this tutorial. DiffusionPipelineProfilerMixin only prints the timing information of multiple functions (such as vae.decode), while torch.profiler saves detailed GPU/CPU computation time, call/execution steps.
This tool automatically measures the execution time of selected pipeline modules and prints the results in the logs.
Enabling Diffusion Pipeline Profiler
Enable timing by setting:
You can optionally specify which modules to profile:class YourPipeline(xxx, DiffusionPipelineProfilerMixin):
def __init__(self, xxx):
...
self.setup_diffusion_pipeline_profiler(profiler_targets=["diffuse"], enable_diffusion_pipeline_profiler)
from vllm_omni.diffusion.profiler import DiffusionPipelineProfilerMixin
class YourModelPipeline(nn.Module, DiffusionPipelineProfilerMixin):
# Optional: Specify custom timing targets
_PROFILER_TARGETS = ["vae.encode", "vae.decode", "diffuse", "text_encoder.forward", "tokenizer.forward"]
def __init__(
self,
*,
od_config: OmniDiffusionConfig,
prefix: str = "",
):
super().__init__()
self.od_config = od_config
self.parallel_config = od_config.parallel_config
# initialize pipeline components
...
# initialize timing profiler
self.setup_diffusion_pipeline_profiler(
enable_diffusion_pipeline_profiler=self.od_config.enable_diffusion_pipeline_profiler
)
If you need to fetch the execution time of different modules, you will need to pass self.stage_durations to DiffusionOutput, as shown below:
- return DiffusionOutput(output=img)
+ return DiffusionOutput(
output=image, stage_durations=self.stage_durations if hasattr(self, "stage_durations") else None
)
Pipeline Design for Timing The current diffusion timing utility is function-based, meaning it measures the execution time of individual methods.
When implementing a new pipeline, avoid putting all logic inside a single function (e.g., forward). Instead, structure the pipeline in a modular way by separating key stages into independent methods, such as the diffusion loop.
For example:
def forward(self, req: DiffusionRequestBatch) -> list[DiffusionOutput]:
prompt_embeds = self.encode_prompt(req)
latents = self.diffuse(prompt_embeds, req)
images = self.vae.decode(latents)
return [DiffusionOutput(output=images)]
Default Profiled Modules
By default, the following pipeline modules are timed:
Example Output
When enabled, timing logs appear like this:
[DiffusionPipelineProfiler] text_encoder.forward took 0.018s
[DiffusionPipelineProfiler] diffuse took 2.412s
[DiffusionPipelineProfiler] vae.decode took 0.063s
Troubleshooting¶
Issue: ImportError when loading model
Symptoms: ModuleNotFoundError or ImportError when calling Omni(model="your-model")
Causes:
- Model not registered in
registry.py - Wrong class name in registry
- Missing
__init__.pyexports
Issue: Shape mismatch in attention
Symptoms: RuntimeError: shape mismatch in attention forward
Cause: Incorrect tensor reshaping for vLLM-Omni's attention interface
Solution: Ensure correct shapes:
# vLLM-Omni expects: [batch, seq_len, num_heads, head_dim]
query = query.view(batch_size, seq_len, self.num_heads, self.head_dim)
key = key.view(batch_size, kv_seq_len, self.num_kv_heads, self.head_dim)
value = value.view(batch_size, kv_seq_len, self.num_kv_heads, self.head_dim)
hidden_states = self.attn(query, key, value, attn_metadata=attn_metadata)
# Reshape back: [batch, seq_len, num_heads, head_dim] → [batch, seq_len, hidden_size]
hidden_states = hidden_states.reshape(batch_size, seq_len, -1)
Issue: Different outputs compared to Diffusers
Symptoms: Generated images look different from Diffusers
Causes:
- Attention backend differences (FlashAttention vs PyTorch SDPA)
- Missing normalization or scaling
4. Issue: Out of memory (OOM)
Symptoms: CUDA out of memory errors
Solutions:
-
Reduce batch size:
-
Use smaller image size:
-
Enable model offloading:
-
Apply vae tiling and slicing
Pull Request Checklist¶
When submitting a PR to add your model, include:
1. Implementation Files
- ✅ Transformer model (
xxx_transformer.py) - ✅ Pipeline (
pipeline_xxx.py) - ✅ Registry entries in
registry.py - ✅
__init__.pywith proper exports
2. Example and Tests
- ✅ Example script in
examples/ - ✅ Test file in
tests/e2e/ - ✅ Documentation (
docs/) creation or updates
Note: End-to-end test files in tests/e2e/ are optional but strongly recommended. README updates are required for all new models.
3. Documentation Updates
- ✅ Add model to supported models table in
docs/models/supported_models.md - ✅ If supporting acceleration features (e.g., sequence parallelism, CFG parallel), update acceleration feature tables in:
docs/user_guide/diffusion_acceleration.mddocs/user_guide/diffusion/parallelism_acceleration.md
Model Recipe¶
After implementing and testing your model, please add a model recipe to the vllm-project/recipes repository. This helps other users understand how to use your model with vLLM-Omni.
What to Include
Your recipe should include:
- Model Overview: Brief description of the model and its capabilities
- Installation Instructions: Step-by-step setup instructions including:
- Installing vllm-omni and dependencies
- Installing any additional required packages (e.g., xformers, diffusers)
- Any version requirements
- Usage Examples: Command-line examples demonstrating how to run the model
- Configuration Details: Important configuration parameters and their meanings
Example
For reference, see the LongCat recipe example which demonstrates the expected format and structure.
Recipe Location
Create your recipe file in the appropriate directory structure: - For organization-specific models: OrganizationName/ModelName.md - For general models: ModelName.md
The recipe should be a Markdown file that provides clear, reproducible instructions for users to get started with your model.
Reference Implementations¶
Study these complete examples:
| Model | Architecture | Key Features | Files |
|---|---|---|---|
| Qwen-Image | Dual-stream transformer | CFG-Parallel, SP, TP, Cache | vllm_omni/diffusion/models/qwen_image/ |
| Wan2.2 | Video transformer | Dual transformers, SP, CFG-Parallel | vllm_omni/diffusion/models/wan2_2/ |
Summary¶
Adding a diffusion model to vLLM-Omni involves:
- ✅ Adapt transformer - Replace attention, remove mixins, add config support
- ✅ Adapt pipeline - Change interface, add request handling, extract processing
- ✅ Register model - Add entries to
registry.py - ✅ Add examples - Provide runnable scripts
- ✅ Test thoroughly - Verify correctness and performance
- ✅ Add advanced features - Enable parallelism and acceleration (optional)
- ✅ Submit PR - Include verification results and documentation
Need help? Check reference implementations or ask in slack.vllm.ai or vLLM user forum at discuss.vllm.ai.