Architecture Overview¶
This document outlines the architectural design for vLLM-Omni.
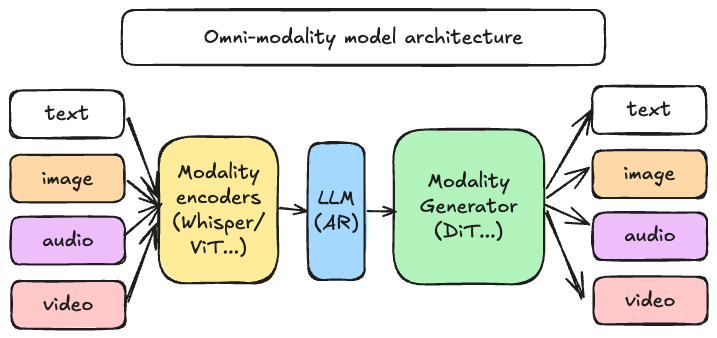
Goals¶
The primary goal of the vLLM-Omni project is to build the fastest and easiest-to-use open-source Omni-Modality model inference & serving engine. vLLM-Omni extends the original vLLM, which was created to support large language models for text-based autoregressive (AR) generation tasks. vLLM-Omni is designed to support:
- Non-textual Output: Enables the integration, efficient processing and output of various data types, including but not limited to, images, audio, and video, alongside text.
- Non-Autoregressive Structure: Support model structure beyond autoregressive, especially Diffusion Transformer (DiT), which is widely used in visual and audio generation.
- Integration with vLLM Core: Maintain compatibility and leverage existing vLLM key modules and optimizations where applicable.
- Extensibility: Design a modular and flexible architecture that can easily accommodate new modalities, model architectures, and output formats.
Representative omni-modality models¶
According to analysis for current popular open-source models, most of them have the combination of AR+DiT. Specifically, they can be further categorized into 3 types below:
DiT as a main structure, with AR as text encoder (e.g.: Qwen-Image) A powerful image generation foundation model capable of complex text rendering and precise image editing.
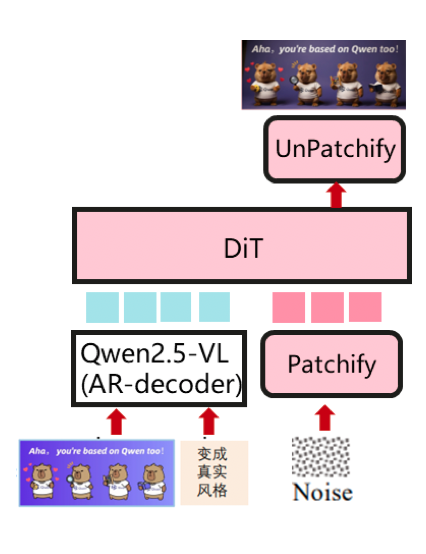
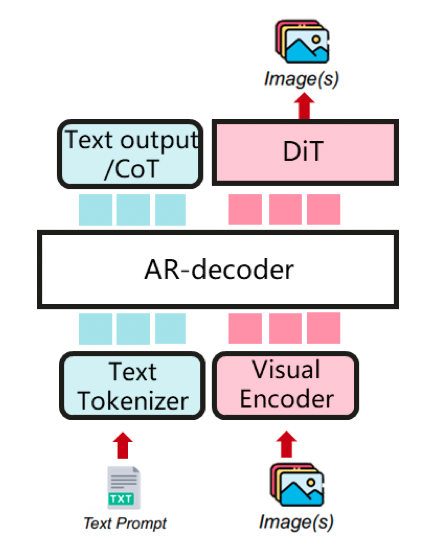
AR as a main structure, with DiT as multi-modal generator (e.g. BAGEL) A unified multimodal comprehension and generation model, with cot text output and visual generation.
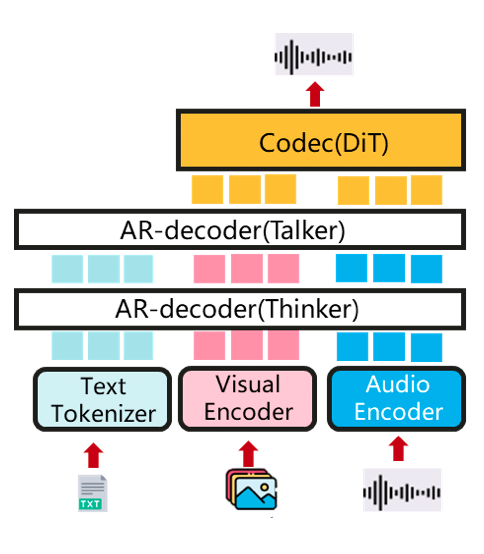
AR+DiT (e.g. Qwen-Omni) A natively end-to-end omni-modal LLM for multimodal inputs (text/image/audio/video...) and outputs (text/audio...).
vLLM-Omni main architecture¶
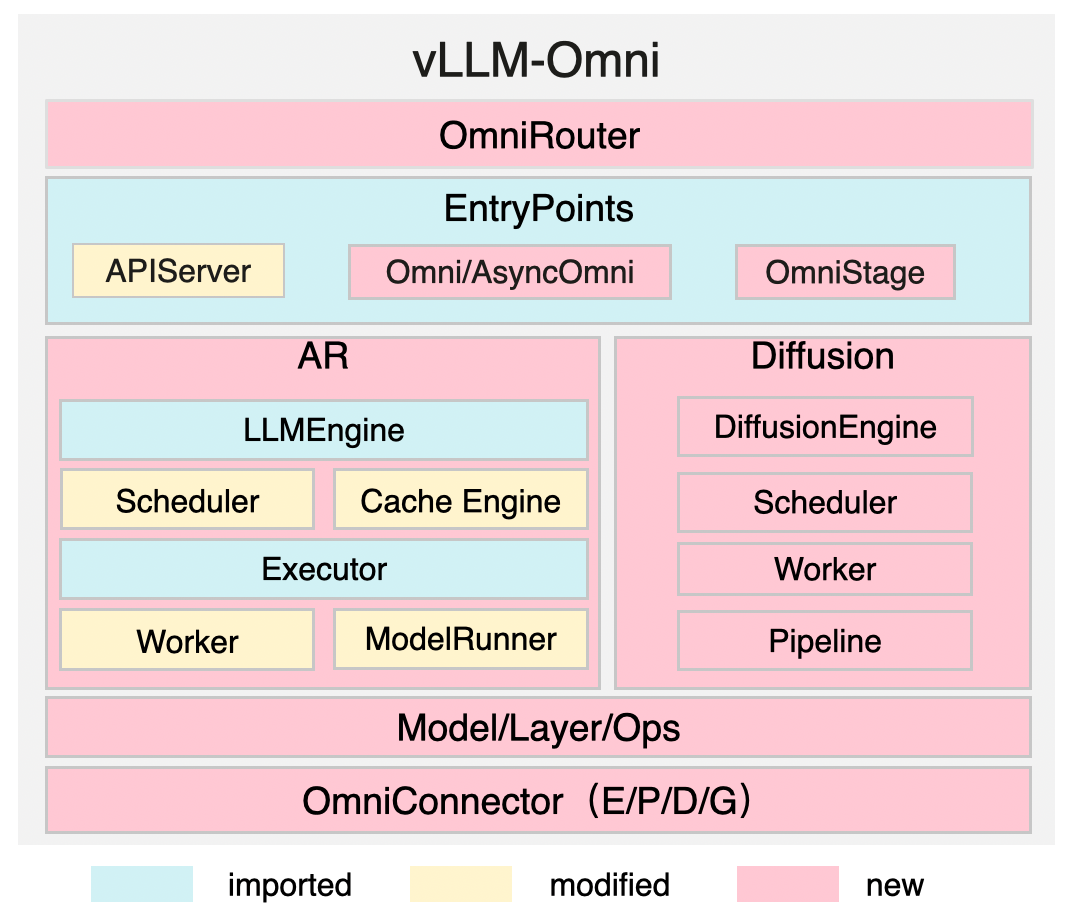
Key Components¶
| Component | Description |
|---|---|
| OmniRouter | provide an intelligent router for Omni-modality requests dispatch |
| EntryPoints | define the APIs for offline/online serving (APIServer, Omni/AsyncOmni), while AsyncOmniEngine and Orchestrator coordinate multi-stage AR/DiT execution |
| AR | adapted for omni-modality models while inheriting efficient features from vLLM, such as cache management |
| Diffusion | natively implemented and optimized using acceleration components |
| OmniConnector | supports fully disaggregation based on E/P/D/G (Encoding/Processing/Decoding/Generation) disaggregation across stages |
Disaggregated stages are managed through stage configuration. In Qwen3-Omni, Thinker/Talker/Code2wav are declared as separate configured stages, and runtime routing is handled by Orchestrator over StageEngineCoreClient / StageDiffusionClient.
Main features¶
vLLM-Omni aims to be fast, flexible, and easy to use with the following features:
Performance and Acceleration¶
The framework achieves high performance through several optimization techniques:
- Efficient AR Support: Leverages efficient KV cache management inherited from vLLM.
- Pipelined Execution: Uses pipelined stage execution overlapping to ensure high throughput.
- Full Disaggregation: Relies on the OmniConnector and dynamic resource allocation across stages.
- Diffusion Acceleration: Includes integrated support for diffusion acceleration. This is managed by the acceleration layer, which handles:
- Cache: Includes DBCache, TeaCache and third-party integration(e.g., cache-dit).
- Parallelism: Supports TP, CP, USP, and CFG.
- Attention: Provides an interface for third-party integration (e.g., FA3, SAGE, MindIE-SD).
- Quantization: Supports various quantization implementations including FP8 and AWQ.
- FusedOps: Allows for custom and third-party integration.
Classifier-Free Guidance (CFG) Companion Flow¶
vLLM-Omni natively models Classifier-Free Guidance (CFG) across disaggregated multi-stage setups via a "companion request" paradigm, eliminating redundant textual/multimodal context computation boundaries: 1. Prompt Expansion: In the initial autoregressive (AR) stage, a customized prompt_expand_func hook intercepts incoming generation prompts and pairs them directly with negative companion prompts (e.g., a default negative prompt) on the fly, tagging the secondary prompt with a specific internal role (cfg_text). 2. Synchronized KV Cache Transfer: The AR stage evaluates both the primary and companion sequence batches concurrently. The OmniConnector captures these specific structural dependencies and reliably passes the positive and negative outcome KV caches seamlessly across stage boundaries via shared memory or network protocols. 3. KV Cache Collection & Injection: Upon reaching the downstream Diffusion (DiT) Engine, an assigned cfg_kv_collect_func automatically intercepts the mapped companion caches (cfg_text_past_key_values). These auxiliary dependencies are natively gathered and seamlessly bound to the primary generation sequence variables, enabling the DiT Engine to cleanly implement cross-attention CFG guidance over accurate conditioning and unconditioning structures in parallel.
Flexibility and Usability¶
vLLM-Omni is designed to be flexible and straightforward for users:
- Heterogeneous Pipeline Abstraction: Manages complex model workflows effectively.
- Hugging Face Integration: Offers seamless integration with popular Hugging Face models.
- Distributed Inference: Supports tensor, pipeline, data, and expert parallelism.
- Streaming Outputs: Supports streaming outputs.
- Unified API: Provides a consistent and unified API interface compatible with vLLM.
- OpenAI-compatible API Server: Includes a FastAPI-based server for online serving that is compatible with the OpenAI API.
Interface design¶
If you use vLLM, then you know how to use vLLM-Omni from Day 0:
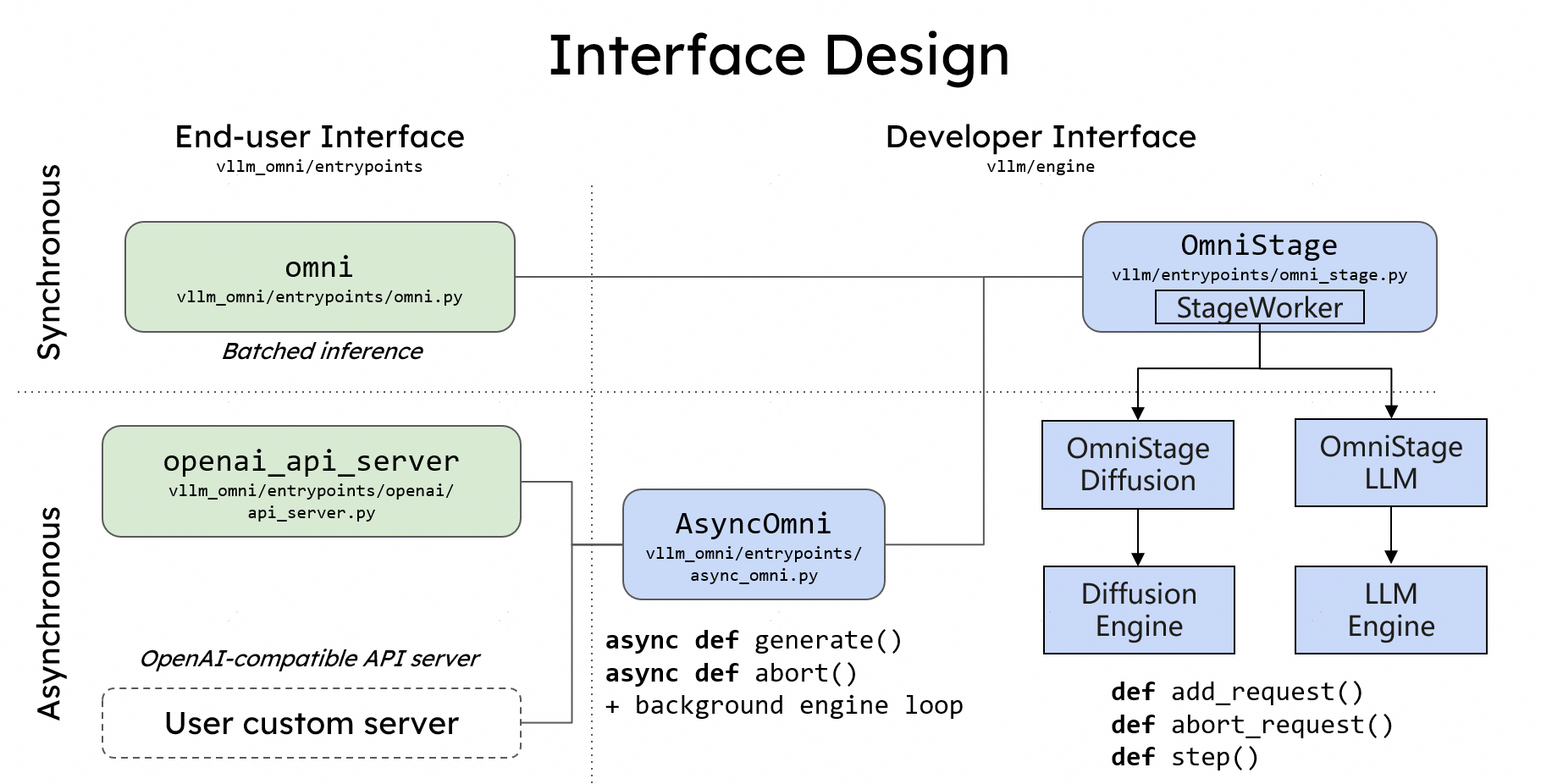
Taking Qwen3-Omni as an example:
Offline Inference¶
The Omni class provides a Python interface for offline batched inference. Users initialize the Omni class with a Hugging Face model name and use the generate method, passing inputs that include both text prompts and multi-modal data:
# Create an omni runtime with HF model name.
from vllm_omni.entrypoints.omni import Omni
omni = Omni(model="Qwen/Qwen3-Omni-30B-A3B-Instruct")
# Example prompts.
om_inputs = {"prompt": prompt,
"multi_modal_data": {
"video": video_frames,
"audio": audio_signal,
}}
# Generate texts and audio from the multi-modality inputs.
outputs = omni.generate(om_inputs, sampling_params_list)
Online Serving¶
Similar to vLLM, vLLM-Omni also provides a FastAPI-based server for online serving. Users can launch the server using the vllm serve command with the --omni flag:
Users can send requests to the server using curl:
# prepare user content
user_content='[
{
"type": "video_url",
"video_url": {
"url": "'"$SAMPLE_VIDEO_URL"'"
}
},
{
"type": "text",
"text": "Why is this video funny?"
}
]'
sampling_params_list='[
'"$thinker_sampling_params"',
'"$talker_sampling_params"',
'"$code2wav_sampling_params"'
]'
mm_processor_kwargs="{}"
# send the request
curl -sS -X POST http://localhost:8091/v1/chat/completions \
-H "Content-Type: application/json" \
-d @- <<EOF
{
"model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
"sampling_params_list": $sampling_params_list,
"mm_processor_kwargs": $mm_processor_kwargs,
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."
}
]
},
{
"role": "user",
"content": $user_content
}
]
}
For more usages, please refer to examples.