Async Chunk¶
Table of Contents¶
Overview¶
The async_chunk feature enables asynchronous, chunked processing of data across multiple stages in a multi-stage pipeline (e.g., Qwen3-Omni with Thinker → Talker → Code2Wav stages). Instead of waiting for a complete stage output before forwarding to the next stage, this feature allows stages to process and forward data in chunks as it becomes available, significantly reducing latency and improving throughput.
Chunk Size Definition
- Prefill Phase:
chunk_size = num_scheduled_tokensfor chunked prefill processing - Decode Phase:
chunk_size = num_scheduled_tokens = 1for per-token streaming
For qwen3-omni: - Thinker → Talker: Per decode step (typically chunk_size=1) - Talker → Code2Wav: Accumulated to codec_chunk_frames (default=25) before sending. During the initial phase, a dynamic initial chunk size (IC) is automatically selected based on server load to reduce TTFP. Use the per-request initial_codec_chunk_frames API field to override. - Code2Wav: Streaming decode with code2wav chunk_size
With async_chunk: - Stages can start processing as soon as chunks are available - Overlapping execution across stages - Reduced latency and improved throughput - Better resource utilization - Async scheduling: Chunk IO (get/put) overlaps with compute via background threads so the scheduler is not blocked waiting for chunks
Performance¶
- Reduced Latency: Next stage can start processing immediately
- Streaming Support: Enables streaming for audio generation
- IO-Compute Overlap: Chunk retrieval happens asynchronously while other requests compute
- Non-blocking Scheduler: Requests waiting for chunks don't block the entire scheduler
- Code2Wav Batch Inference: Supports batched processing in code2wav stage
| Input | Output | Async_chunk enabled | Code2Wav batch size | Max_Concurrency | Prompts | Mean E2E | Mean TTFT | Mean TPOT | Mean TTFP | Mean RTF | Mean ITL |
|---|---|---|---|---|---|---|---|---|---|---|---|
| text 100 | text 100+audio | False | 1 | 1 | 50 | 6581.80 | 43.22 | 8.31 | 6459.34 | 0.24 | 8.22 |
| text 100 | text 100+audio | False | 1 | 4 | 50 | 7398.63 | 67.57 | 9.14 | 7285.35 | 0.27 | 9.05 |
| text 100 | text 100+audio | False | 1 | 10 | 50 | 13522.99 | 131.82 | 12.72 | 13410.44 | 0.49 | 12.60 |
| text 100 | text 100+audio | False | 64 | 1 | 50 | 6505.13 | 43.14 | 8.52 | 6395.40 | 0.24 | 8.44 |
| text 100 | text 100+audio | False | 64 | 4 | 50 | 7668.15 | 51.15 | 9.36 | 7562.37 | 0.28 | 9.27 |
| text 100 | text 100+audio | False | 64 | 10 | 50 | 9516.18 | 138.06 | 14.75 | 9409.26 | 0.34 | 14.60 |
| text 100 | text 100+audio | True | 1 | 1 | 50 | 6179.79 | 44.58 | 8.69 | 522.99 | 0.22 | 8.60 |
| text 100 | text 100+audio | True | 1 | 4 | 50 | 7692.69 | 103.96 | 10.22 | 785.85 | 0.29 | 10.12 |
| text 100 | text 100+audio | True | 1 | 10 | 50 | 11152.71 | 685.60 | 17.64 | 1628.88 | 0.41 | 17.62 |
Performance data collected on H800 GPUs through comprehensive benchmarking with cudagraph enabled. text input uses random dataset.
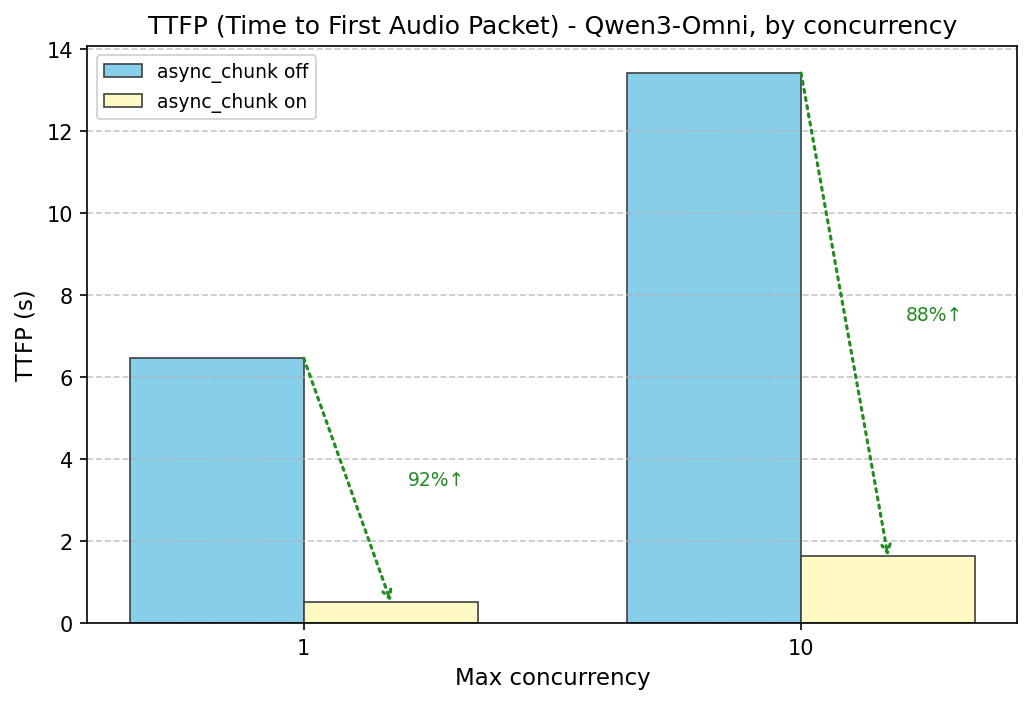
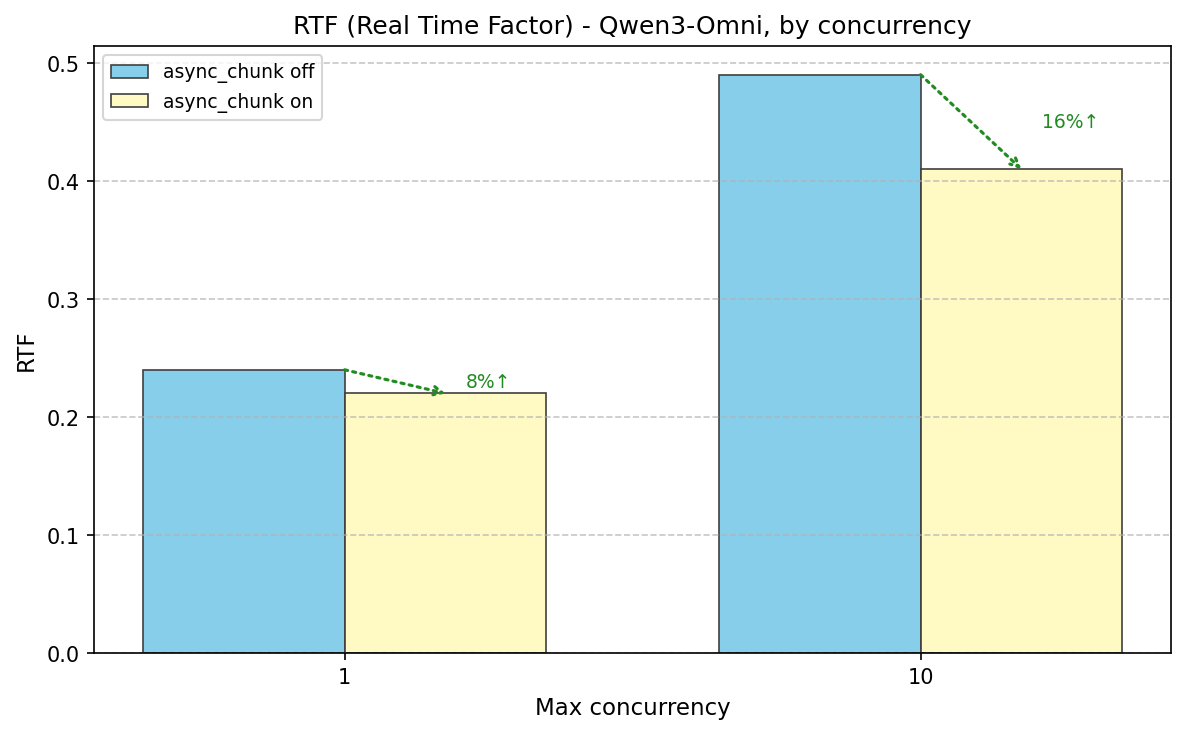
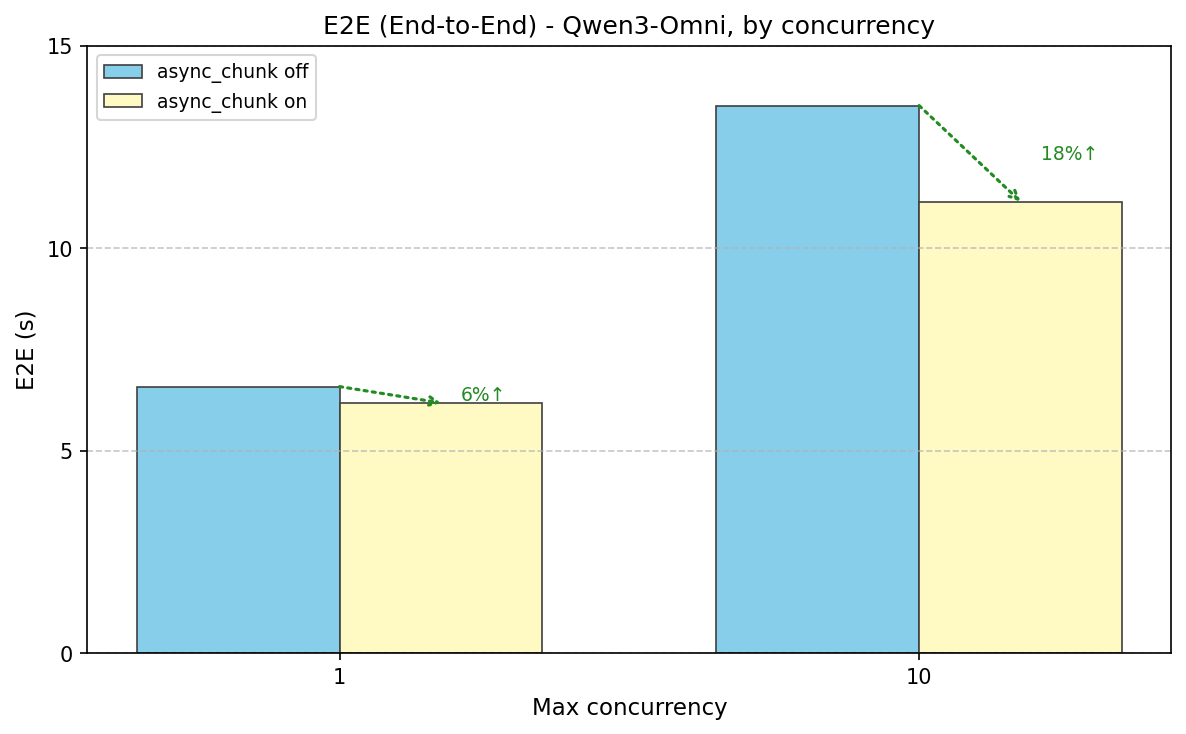
Enabling async_chunk (False→True) sharply reduces time-to-first-audio (TTFP)—e.g. ~92% at concurrency 1 (6.5s→0.52s)—and improves E2E latency (e.g. ~6% at conc 1, ~17% at conc 10). RTF (Real Time Factor) also improves with async_chunk on (e.g. ~8% at conc 1: 0.24→0.22, ~16% at conc 10: 0.49→0.41). Enabling Code2Wav batch size 64 (vs 1) improves E2E and TTFP at higher concurrency when async_chunk is off (e.g. ~30% at conc 10: 13.5s→9.5s E2E, 13.4s→9.4s TTFP).
Architecture¶
Async Chunk Pipeline Overview¶
The following diagram illustrates the Async Chunk Architecture for multi-stage models (e.g., Qwen3-Omni with Thinker → Talker → Code2Wav), showing how data flows through the 4-stage pipeline with parallel processing and dual-stream output:
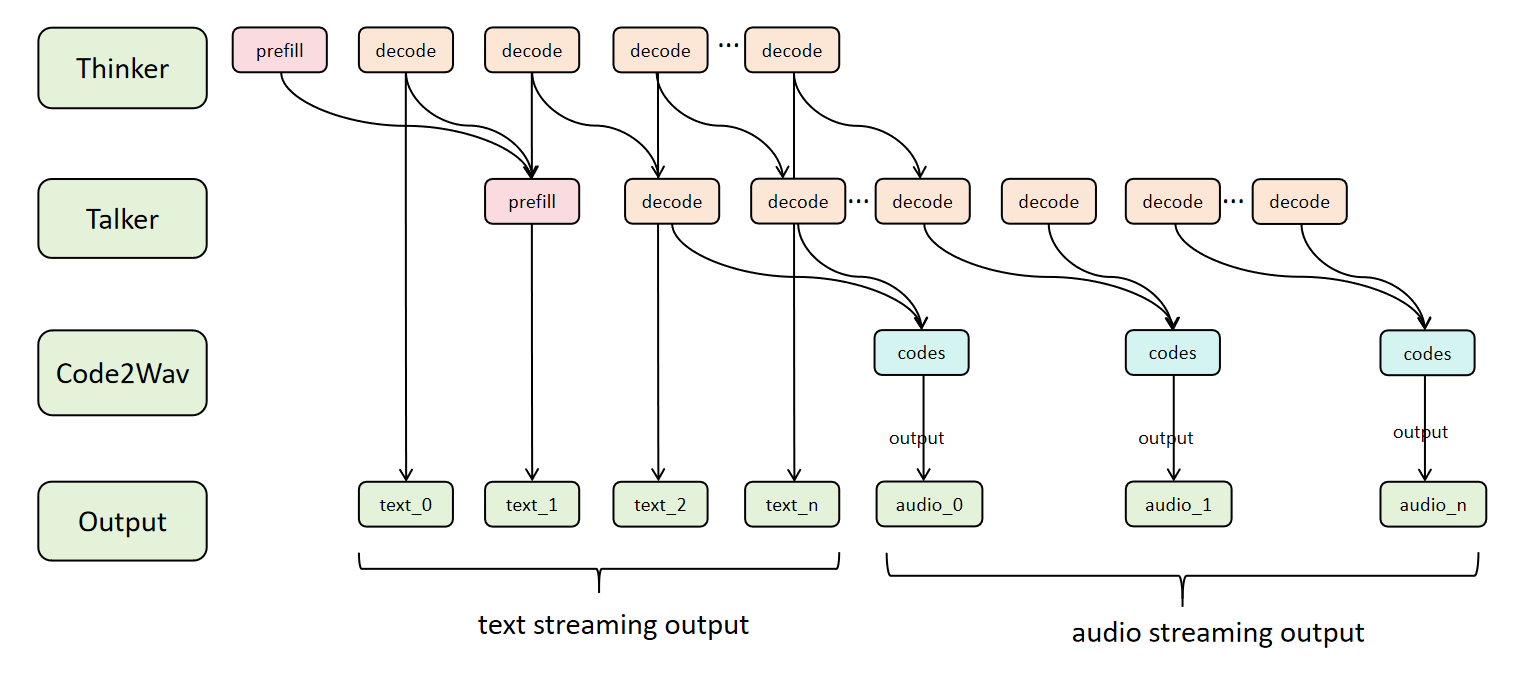
Diagram Legend:
| Step | Stage Type | Description |
|---|---|---|
prefill | Initialization | Context processing, KV cache initialization |
decode | Autoregressive | Token-by-token generation in AR stages |
codes | Audio Encoding | RVQ codec codes from Talker stage |
output | Final Output | Text chunks or audio waveforms |
Data Flow¶
Stage 0: Thinker (Multimodal Understanding + Text Generation)¶
- Prefill: Processes multimodal input (text/image/audio/video), initializes KV cache
- Decode Loop: Generates text tokens autoregressively
- Chunk Triggers: Each decode step (typically
chunk_size=1) can trigger downstream processing - Dual Output:
- Text Stream:
text_0,text_1,text_2...text_nstreamed to output - Hidden States: Passed to Talker stage for audio synthesis
Stage 1: Talker (Text → RVQ Audio Codes)¶
- Prefill: Receives hidden states from Thinker as semantic condition
- Decode Loop: Generates RVQ codec codes autoregressively
- Accumulation: Codes accumulate to
codec_chunk_frames(default=25) before forwarding - Dynamic IC: Initial chunk size auto-selected based on server load to optimize TTFP
- Output:
codesblocks (chunk 0, 1, ... n) sent to Code2Wav
Stage 2: Code2Wav (Vocoder Decoder)¶
- Non-Autoregressive: Processes RVQ codes in parallel batches
- Streaming Decode: Converts codes to audio waveforms chunk-by-chunk
- Batching: Supports batched inference for multiple concurrent requests
- Output: Audio segments
audio_0,audio_1, ...audio_n
Stage 3: Output (Dual Stream)¶
- Text Streaming:
text_0→text_1→text_2→ ... (user sees response in real-time) - Audio Streaming:
audio_0→audio_1→ ... (user hears audio progressively)
Execution Timeline¶
Timeline: Parallel vs Sequential
Sequential (async_chunk=false):
[Thinker: ████████████████████] (2.0s)
[Talker: ████████████████████] (3.0s)
[Code2Wav: ████] (1.0s)
Total: 6.0s, TTFP: 6.0s
Async Chunk (async_chunk=true):
[Thinker: ████░░░░████░░░░████] (2.0s, streaming)
[Talker: ░░████░░░░████░░] (3.0s, parallel)
[Code2Wav: ░░░░████░░] (1.0s, batched)
Total: ~3.5s, TTFP: ~0.5s
█ = Active computation ░ = Waiting/idle
Sequential Flow (for comparison)¶
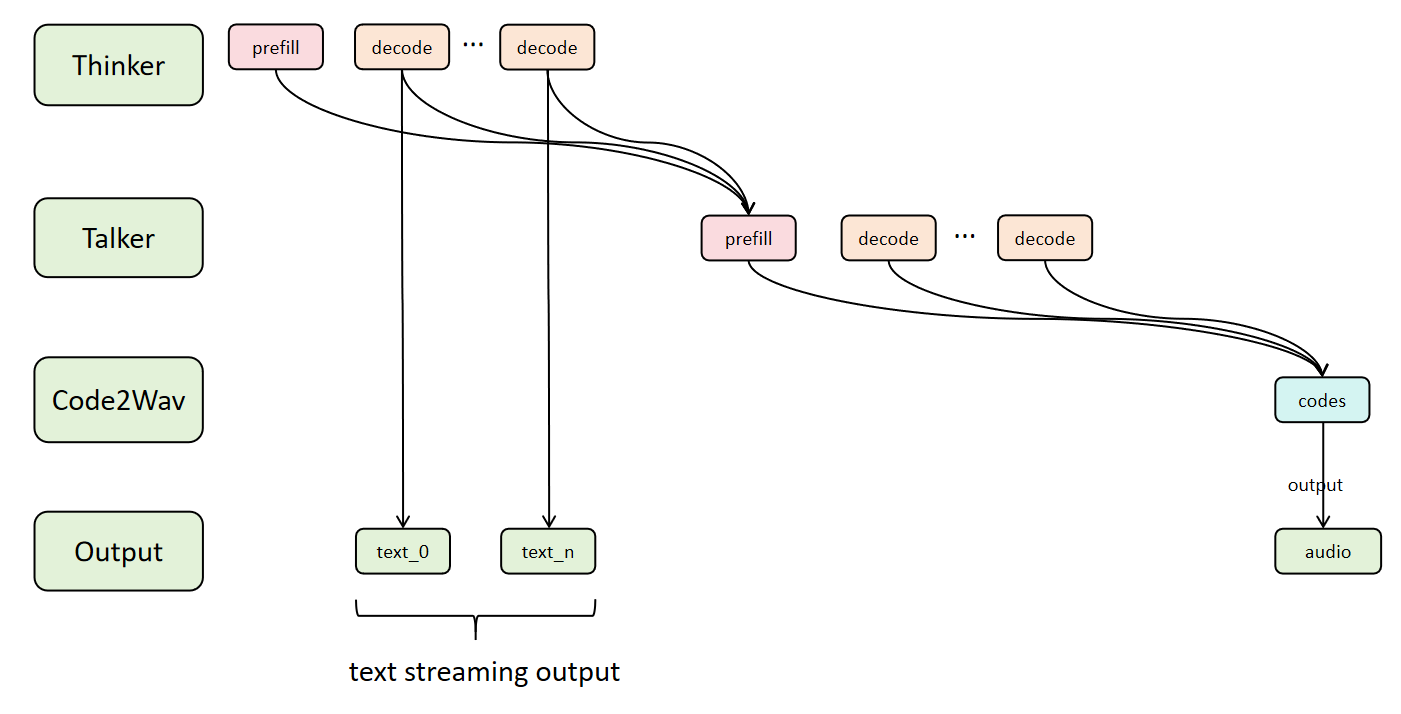
In sequential mode, each stage must wait for the previous stage to complete entirely before starting.
Async Chunk System Architecture¶
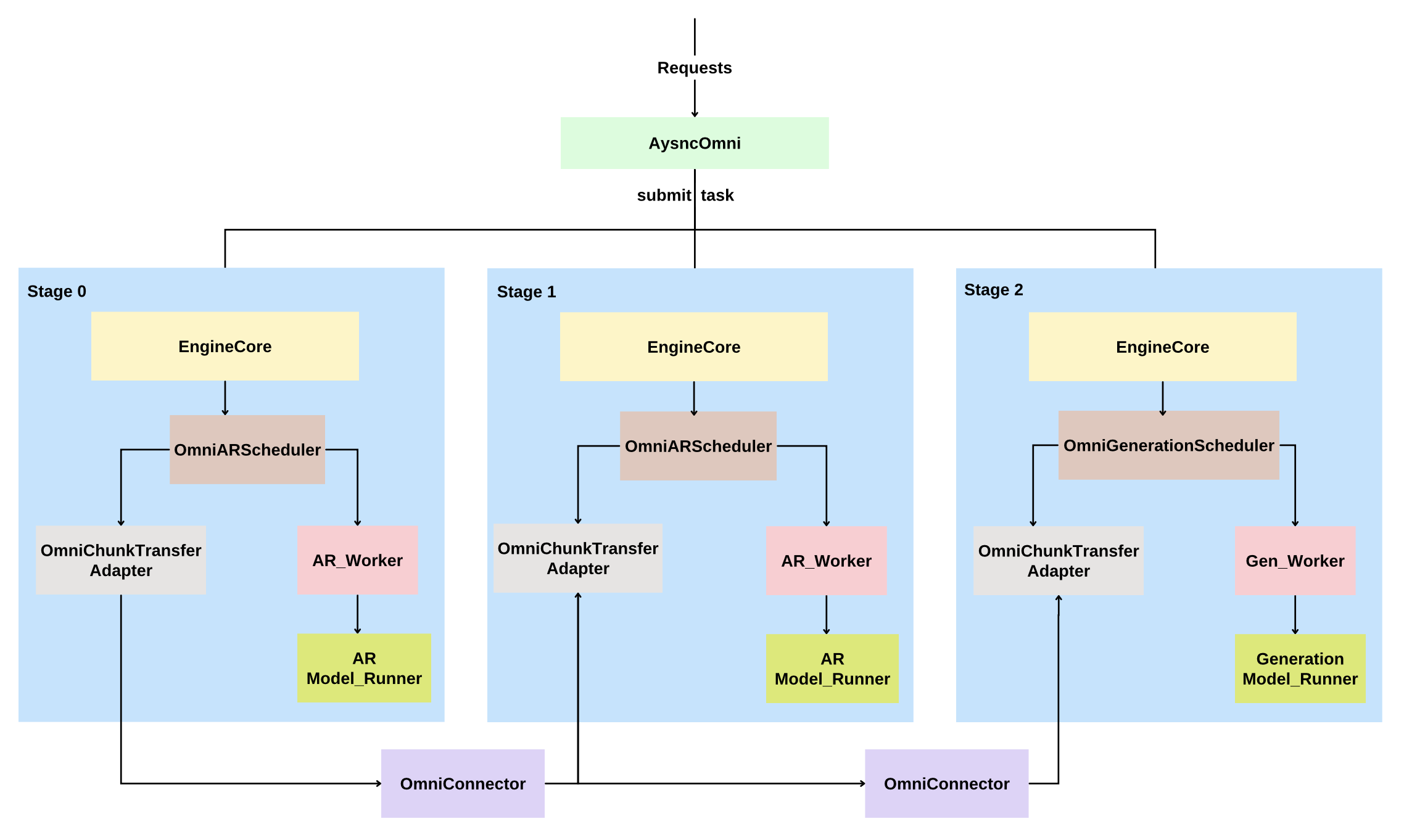
Key Components¶
- OmniConnector: Inter-stage data transport only
- Shared memory or other IPC mechanisms
- Transport-only API:
put(from_stage, to_stage, put_key, data)andget(from_stage, to_stage, get_key)(optionally with timeout) - No request-specific state: Connector does not track put_requests, get_requests, request_payload, finished_requests, or other request-bound metadata; it only performs put/get operations
-
Chunk keys and request/chunk lifecycle are managed by OmniChunkTransferAdapter
-
Transfer Adapter Layer: Extensible abstraction for managing data transfer via connectors
- OmniTransferAdapterBase: Base class with background recv_loop and save_loop threads;
-
OmniChunkTransferAdapter: Chunk-specific implementation that owns the full chunk lifecycle when async_chunk is enabled
- Chunk ID and key construction: Builds keys like
{req_id}_{stage_id}_{chunk_id}for put/get - Async get:
load_async(request)enqueues the request; background recv_loop polls the connector (non-blocking); when data is available, updates the request and marks it in_finished_load_reqs; scheduler callsget_finished_requests()to learn which requests have chunks ready - Async put:
save_async(pooling_output, request)invokescustom_process_next_stage_input_funcin the main thread to build the payload, then enqueues a save task; background save_loop performsconnector.put(); payload processing and chunk accumulation (e.g. code2wav chunk_size) remain in the main thread
- Chunk ID and key construction: Builds keys like
-
Stage Input Processors: Custom functions that process stage outputs into chunks for different models
- Receive transfer_manager (OmniChunkTransferAdapter)
-
Qwen3-omni reference:
thinker2talker_async_chunk,talker2code2wav_async_chunk -
Schedulers: Modified to handle chunk-based scheduling with async IO-compute overlap
OmniARScheduler: For autoregressive stagesOmniGenerationScheduler: For generation stages- Both schedulers use OmniChunkTransferAdapter and before/after hooks around
super().schedule():- Before
super().schedule():process_pending_chunks(waiting, running)moves requests waiting for chunks toWAITING_FOR_CHUNK, enqueues load tasks for background polling - After
super().schedule():restore_queues(waiting, running)restores requests with ready chunks back to waiting/running,postprocess_scheduler_output(scheduler_output)attaches cached additional_information, clears chunk-ready flags
- Before
-
put_chunk
save_async(pooler_output, request); get_chunk / get_chunk_for_generationload_async(request) -
Model Runners: Handle chunk processing
OmniGPUModelRunner: Processes chunks in AR stages-
GPUGenerationModelRunner: Processes chunks in generation stages- Uses
ubatch_slicesfromget_forward_context()to track per-request sequence lengths in batched inference - Reuses
ubatch_slices_paddedfor code2wav batching to properly split batch outputs - Handles list-type multimodal outputs: iterates through requests and assigns corresponding tensor to each
- Improved request state management: removes unscheduled and finished requests from input batch
- Uses
-
Model Implementation: Model-specific chunk handling
Qwen3OmniMoeForConditionalGeneration: Main model with async_chunk support- Code2Wav stage batching: Uses
ubatch_slicesto construct batched codec codes tensor[batch_size, 16, max_seq_len] - Batch output handling:
generate_audio()returnslist[torch.Tensor], one audio tensor per request - Multimodal outputs: Returns list of audio tensors for batch processing instead of single concatenated tensor
- Code2Wav stage batching: Uses
-
Qwen3OmniCode2WavDecoder: Audio generation modelchunked_decode()andchunked_decode_streaming(): Returnlist[torch.Tensor](one per request)- Uses
ubatch_slicesto split batched waveform output into per-request audio chunks - Each request gets correctly sized audio based on its code sequence length:
waveform[:, :, :code_seq_len * total_upsample]
-
Request status:
RequestStatus.WAITING_FOR_CHUNKis added via patch (e.g. invllm_omni/patch.py) so requests waiting for a chunk are not scheduled by the base vLLM scheduler until the chunk is ready.
Configuration¶
Enable async_chunk in stage configuration YAML:
async_chunk: true
stage_args:
- stage_id: 0
engine_args:
custom_process_next_stage_input_func: vllm_omni.model_executor.stage_input_processors.qwen3_omni.thinker2talker_async_chunk
- stage_id: 1
engine_args:
custom_process_next_stage_input_func: vllm_omni.model_executor.stage_input_processors.qwen3_omni.talker2code2wav_async_chunk
Stage Configuration¶
async_chunk: bool: Enable/disable async chunk modecustom_process_next_stage_input_func: str: Path to custom chunk processing function; receives(transfer_manager, pooling_output, request). For qwen3-omni:thinker2talker_async_chunk,talker2code2wav_async_chunkstage_connector_config: dict: Connector configurationworker_type: str: Model type, e.g."ar"or"generation"(used by OmniChunkTransferAdapter for mode-specific payload handling)max_num_seqs: int: Maximum number of sequences for concurrent processing in the stage
Connector Configuration¶
Code2Wav Batch Configuration¶
For optimal performance with async_chunk, the code2wav stage should be configured with batching:
stage_args:
- stage_id: 2 # code2wav stage
runtime:
devices: "1"
engine_args:
model_stage: code2wav
max_num_seqs: 64 # Enables batched audio generation
Related Files¶
vllm_omni/model_executor/stage_input_processors/qwen3_omni.py: Chunk processing functions (receivetransfer_manageras first param)vllm_omni/distributed/omni_connectors/transfer_adapter/base.py: OmniTransferAdapterBase (recv_loop, save_loop, load_async, save_async)vllm_omni/distributed/omni_connectors/transfer_adapter/chunk_transfer_adapter.py: OmniChunkTransferAdapter (process_pending_chunks, restore_queues, postprocess_scheduler_output)vllm_omni/distributed/omni_connectors/connectors/shm_connector.py: SharedMemoryConnector (transport-only put/get)vllm_omni/core/sched/omni_ar_scheduler.py: AR scheduler with chunk_transfer_adaptervllm_omni/core/sched/omni_generation_scheduler.py: Generation scheduler with same async chunk patternvllm_omni/worker/gpu_model_runner.py: Model runner with chunk handlingvllm_omni/worker/gpu_generation_model_runner.py: Generation model runner with batch output handling and ubatch_slices supportvllm_omni/model_executor/models/qwen3_omni/qwen3_omni.py: Model implementation with code2wav batchingvllm_omni/model_executor/models/qwen3_omni/qwen3_omni_code2wav.py: Code2wav decoder with batch supportvllm_omni/engine/arg_utils.py: Configuration definitions (async_chunk, worker_type)vllm_omni/config/model.py: Model config with async_chunk field