量化适配#
本文档提供了与 ModelSlim 相关的量化算法和模型适配指南。
量化功能介绍#
量化推理流程#
当前 vLLM Ascend 中注册并获取量化方法的过程如下:
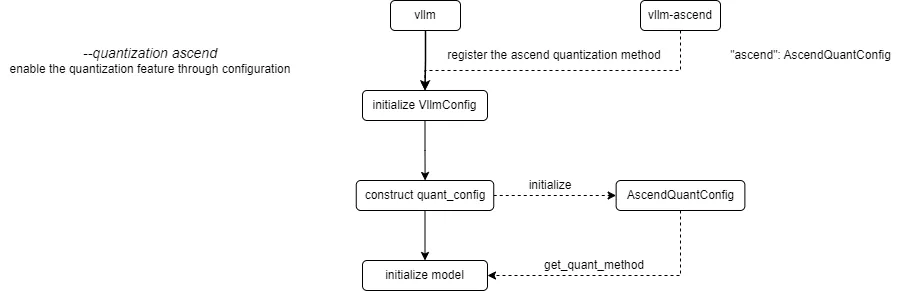
vLLM Ascend 注册了自定义的 ascend 量化方法。通过配置 --quantization ascend 参数(或离线模式下的 quantization="ascend")来启用量化功能。构建 quant_config 时,会初始化已注册的 AscendQuantConfig,并调用 get_quant_method 来获取与每个权重部分对应的量化方法,存储在 quant_method 属性中。
目前支持的量化方法包括 AscendLinearMethod、AscendFusedMoEMethod、AscendEmbeddingMethod 及其对应的非量化方法:
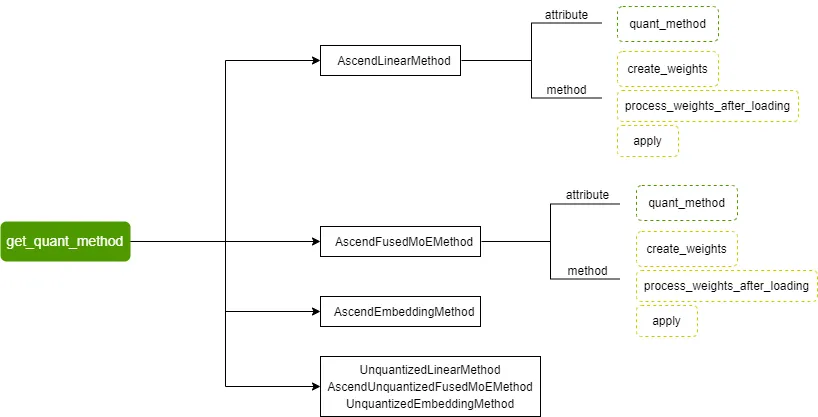
vLLM 定义的量化方法基类及量化方法的整体调用流程如下:
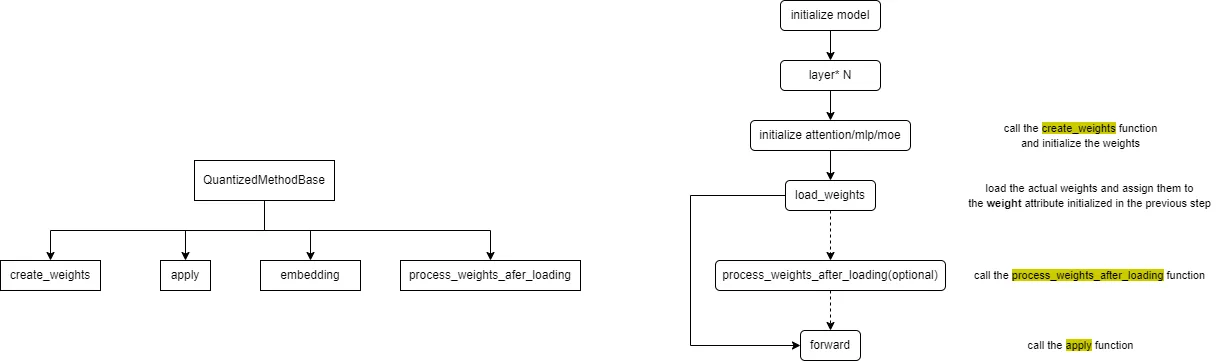
embedding 方法通常不实现量化,重点在于其他三种方法。
create_weights 方法用于权重初始化;process_weights_after_loading 方法用于权重后处理,例如转置、格式转换、数据类型转换等;apply 方法用于在前向过程中执行激活量化和量化矩阵乘法计算。
我们需要为不同的层(attention、mlp、moe)实现 create_weights、process_weights_after_loading 和 apply 方法。
补充说明:加载模型时,需要读取量化模型的描述文件 quant_model_description.json。该文件描述了模型权重各个部分的量化配置和参数,例如:
{
"model.layers.0.linear_attn.dt_bias": "FLOAT",
"model.layers.0.linear_attn.A_log": "FLOAT",
"model.layers.0.linear_attn.conv1d.weight": "FLOAT",
"model.layers.0.linear_attn.in_proj_qkvz.weight": "W8A8_DYNAMIC",
"model.layers.0.linear_attn.in_proj_qkvz.weight_scale": "W8A8_DYNAMIC",
"model.layers.0.linear_attn.in_proj_qkvz.weight_offset": "W8A8_DYNAMIC",
"model.layers.0.linear_attn.in_proj_ba.weight": "FLOAT",
"model.layers.0.linear_attn.norm.weight": "FLOAT",
"model.layers.0.linear_attn.out_proj.weight": "FLOAT",
"model.layers.0.mlp.gate.weight": "FLOAT",
"model.layers.0.mlp.experts.0.gate_proj.weight": "W8A8_DYNAMIC",
"model.layers.0.mlp.experts.0.gate_proj.weight_scale": "W8A8_DYNAMIC",
"model.layers.0.mlp.experts.0.gate_proj.weight_offset": "W8A8_DYNAMIC",
}
基于以上内容,我们对量化算法和量化模型的适配过程进行简要描述。
量化算法适配#
步骤 1:算法设计。定义算法 ID(例如
W4A8_DYNAMIC),确定支持的层(线性层、moe、attention),并设计量化方案(静态/动态、按张量/按通道/按分组)。步骤 2:注册。将算法 ID 添加到
vllm_ascend/quantization/utils.py中的ASCEND_QUANTIZATION_METHOD_MAP,并将其与对应的方法类关联。
ASCEND_QUANTIZATION_METHOD_MAP: Dict[str, Dict[str, Type[Any]]] = {
"W4A8_DYNAMIC": {
"linear": AscendW4A8DynamicLinearMethod,
"moe": AscendW4A8DynamicFusedMoEMethod,
},
}
步骤 3:实现。创建算法实现文件,例如
vllm_ascend/quantization/w4a8_dynamic.py,并实现方法类及其逻辑。步骤 4:测试。使用您的算法生成量化配置,并在目标模型和硬件上验证正确性与性能。
量化模型适配#
适配新的量化模型需要确保以下三点:
原始模型已在
vLLM Ascend中成功适配。融合模块映射:将模型的
model_type添加到vllm_ascend/quantization/quant_config.py中的packed_modules_model_mapping(例如qkv_proj、gate_up_proj、experts),以确保分片一致性和正确加载。
packed_modules_model_mapping = {
"qwen3_moe": {
"qkv_proj": [
"q_proj",
"k_proj",
"v_proj",
],
"gate_up_proj": [
"gate_proj",
"up_proj",
],
"experts":
["experts.0.gate_proj", "experts.0.up_proj", "experts.0.down_proj"],
},
}
量化模型使用的所有量化算法都已集成到
quantization模块中。
当前支持的量化算法#
vLLM Ascend 支持多种量化算法。下表基于 vllm_ascend.quantization 模块中的实现,概述了每种量化算法:
算法 |
权重 |
激活 |
权重粒度 |
激活粒度 |
类型 |
描述 |
|---|---|---|---|---|---|---|
|
INT4 |
FP16/BF16 |
按分组 |
按张量 |
静态 |
4 位权重量化,16 位激活精度,专为 MoE 模型专家层设计,支持 int32 格式的权重打包 |
|
INT8 |
FP16/BF16 |
按通道 |
按张量 |
静态 |
8 位权重量化,16 位激活精度,在精度和性能间取得平衡,适用于线性层 |
|
INT8 |
INT8 |
按通道 |
按张量 |
静态 |
静态激活量化,适用于需要高精度的场景 |
|
INT8 |
INT8 |
按通道 |
按 token |
动态 |
动态激活量化,按 token 计算缩放因子 |
|
INT4 |
INT8 |
按分组 |
按 token |
动态 |
支持直接按通道量化到 4 位,以及两步量化(先按通道量化到 8 位,再按分组量化到 4 位) |
|
INT4 |
INT4 |
按通道 |
按 token |
动态 |
在 4 位动态量化前使用 FlatQuant 对激活分布进行平滑处理,并通过额外的矩阵乘法来保持精度 |
|
INT8 |
INT8 |
按通道 |
按张量/token |
混合 |
PD 共置场景下,P 节点和 D 节点均使用动态量化;PD 分离场景下,P 节点使用动态量化,D 节点使用静态量化 |
静态与动态: 静态量化使用预计算的缩放因子,性能更佳;动态量化则为每个 token/激活张量实时计算缩放因子,精度更高。
粒度: 指缩放因子计算的范围(例如,按张量、按通道、按分组)。