分离式编码器¶
分离式编码器是指将大语言模型(LLM)的视觉(多模态)编码阶段,在与语言模型的预填充和解码阶段分离的独立 vLLM 进程/实例中运行。
类似地,分离式预填充将提示处理(KV 缓存计算)与自回归令牌生成(解码阶段)隔离到不同的 vLLM 实例中。
这种分离允许针对每个阶段进行硬件和资源的定向优化,从而能够精确调整首令牌时间(TTFT)与令牌间延迟(ITL)。因此,它提高了高负载服务期间的整体吞吐量和资源利用率。
预填充-解码(PD)分离是该机制的总体架构。在这种设置中,专用的预填充实例计算 KV 缓存,并通过 MooncakeLayerwise 等专用连接器将其传输到解码实例以进行令牌生成。
在 vLLM(包括 Ascend 硬件插件)等框架中,PD 分离通常与多模态模型的编码器-预填充-解码(EPD)架构集成,同时支持具有分布式负载均衡的多节点配置。
最终,这些架构模式通过解决每个阶段对比鲜明的计算特征来最大化推理效率:编码和预填充是计算密集型和突发性的,而解码是内存密集型和持续性的。
为什么使用分离式编码器?¶
**分离式编码器**在与预填充/解码阶段分离的进程中运行多模态 LLM 的视觉编码阶段。将这两个阶段部署在独立的 vLLM 实例中带来了三个实际好处:
-
独立、细粒度的扩展
-
视觉编码器是轻量级的,而语言模型则大几个数量级。
- 语言模型可以并行化,而不会影响编码器集群。
-
编码器节点可以独立添加或移除。
-
更低的首令牌时间(TTFT)
-
纯语言请求完全绕过视觉编码器。
-
编码器输出仅在所需的注意力层注入,缩短了预填充关键路径。
-
编码器输出的跨进程复用和缓存
-
进程内编码器将复用限制在单个工作节点内。
- 远程共享缓存允许任何工作节点检索现有的嵌入,从而消除冗余计算。
设计文档:https://docs.google.com/document/d/1aed8KtC6XkXtdoV87pWT0a8OJlZ-CpnuLLzmR8l9BAE/edit
使用方法¶
当前参考路径为 ExampleConnector。 以下可直接运行的脚本展示了工作流程:
1 个编码器实例 + 1 个 PD 实例:
examples/online_serving/disaggregated_encoder/disagg_1e1pd/
1 个编码器实例 + 1 个预填充实例 + 1 个解码实例:
examples/online_serving/disaggregated_encoder/disagg_1e1p1d/
开发¶
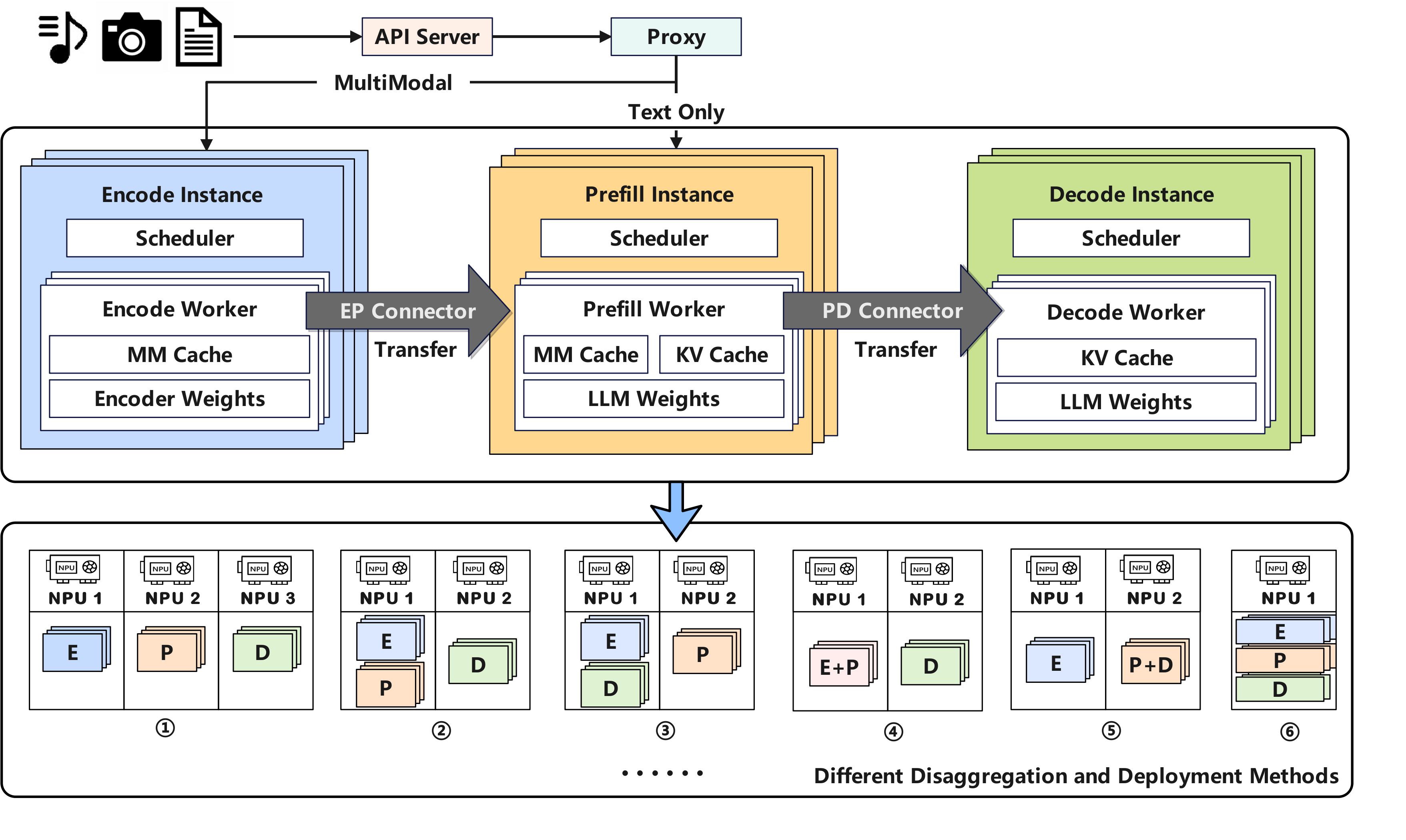
分离式编码通过运行两个部分来实现:
- 编码器实例 – 执行视觉编码的 vLLM 实例。
- 预填充/解码(PD)实例 – 运行语言预填充和解码。
- PD 可以位于单个普通实例(E + PD)中,也可以位于分离式实例(E + P + D)中
连接器将编码器缓存(EC)嵌入从编码器实例传输到 PD 实例。
所有相关代码位于 vllm/distributed/ec_transfer 下。
关键抽象¶
-
ECConnector – 用于检索编码器产生的 EC 缓存的接口。
- 调度器角色 – 检查缓存是否存在并调度加载。
- 工作节点角色 – 将嵌入加载到内存中。
-
EPD 负载均衡代理 -
- 多路径调度策略 - 动态地将多模态请求或文本请求分流到相应的推理路径
- 实例级动态负载均衡 - 基于最少负载策略分发多模态请求,使用优先级队列来平衡各实例间的活跃令牌工作负载。
我们使用来自 vllm_ascend/distributed/kv_transfer/kv_p2p/mooncake_layerwise_connector.py 的 MooncakeLayerwiseConnector 创建示例设置,并参考 examples/disaggregated_prefill_v1/load_balance_proxy_layerwise_server_example.py 来促进 P 和 D 之间的 KV 传输。有关 Mooncake 的逐步部署和配置,请参考以下指南:
https://docs.vllm.ai/projects/ascend/en/latest/tutorials/features/pd_disaggregation_mooncake_multi_node.html
对于 PD 分离部分,当使用 MooncakeLayerwiseConnector 时:请求首先进入解码器实例,解码器通过元服务器反向触发远程预填充任务。然后预填充节点执行推理并逐层将 KV 缓存推送到解码器,使计算与传输重叠。一旦传输完成,解码器无缝地继续进行后续的令牌生成。
docs/source/developer_guide/Design_Documents/disaggregated_prefill.md 展示了关于分离式预填充的简要概念。
限制¶
-
如果要使用跨进程缓存,请禁用
--mm-processor-cache-gb 0 -
对于 PD 分离部分,请参考 PD 分解的限制