多节点测试#
多节点CI旨在测试超大规模模型的分布式场景,例如:跨多节点的解耦预填充(disaggregated_prefill)、多数据并行(multi DP)等。
工作原理#
下图展示了多节点CI机制的基本部署视图。它说明了GitHub Action如何与lws(一种Kubernetes CRD资源)进行交互。
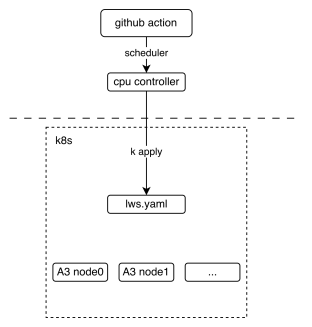
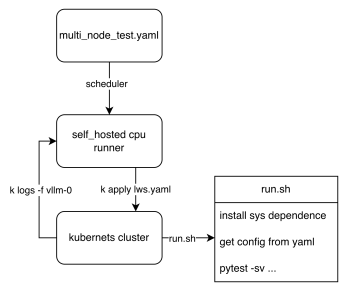
从工作流的角度,我们可以看到最终的测试脚本是如何执行的。关键在于这两个文件:lws.yaml和run.sh。前者定义了我们的k8s集群如何被拉起,后者定义了Pod启动时的入口脚本。每个节点根据LWS_WORKER_INDEX环境变量执行不同的逻辑,从而使多个节点能够组成一个分布式集群来执行任务。
如何贡献#
上传自定义权重
如果您需要自定义权重,例如,您为DeepSeek-V3量化了一个w8a8权重,并希望您的权重能在CI上运行,欢迎将权重上传至ModelScope的vllm-ascend组织。如果您没有上传权限,请联系@Potabk。
添加配置YAML
如入口脚本run.sh所示,一个k8s Pod的启动意味着遍历目录中的所有*.yaml文件,并根据不同的配置读取和执行。因此,我们需要做的就是添加类似DeepSeek-V3.yaml的"yaml"文件。
假设您有2个节点运行1P1D设置(1个预填充器 + 1个解码器):
您可以添加一个类似这样的配置文件:
test_name: "test DeepSeek-V3 disaggregated_prefill" # the model being tested model: "vllm-ascend/DeepSeek-V3-W8A8" # how large the cluster is num_nodes: 2 npu_per_node: 16 # All env vars you need should add it here env_common: VLLM_USE_MODELSCOPE: true OMP_PROC_BIND: false OMP_NUM_THREADS: 100 HCCL_BUFFSIZE: 1024 SERVER_PORT: 8080 disaggregated_prefill: enabled: true # node index(a list) which meet all the conditions: # - prefiller # - no headless(have api server) prefiller_host_index: [0] # node index(a list) which meet all the conditions: # - decoder decoder_host_index: [1] # Add each node's vllm serve cli command just like you run locally # Add each node's individual envs like follow deployment: - envs: # fill with envs like: <key>:<value> server_cmd: > vllm serve ... - envs: # fill with envs like: <key>:<value> server_cmd: > vllm serve ... benchmarks: perf: # fill with performance test kwargs acc: # fill with accuracy test kwargs
将用例添加到夜间工作流
目前,多节点测试工作流定义在nightly_test_a3.yaml中。
```yaml
multi-node-tests:
name: multi-node
if: always() && (github.event_name == 'schedule' || github.event_name == 'workflow_dispatch')
strategy:
fail-fast: false
max-parallel: 1
matrix:
test_config:
- name: multi-node-deepseek-pd
config_file_path: DeepSeek-V3.yaml
size: 2
- name: multi-node-qwen3-dp
config_file_path: Qwen3-235B-A22B.yaml
size: 2
- name: multi-node-qwenw8a8-2node
config_file_path: Qwen3-235B-W8A8.yaml
size: 2
- name: multi-node-qwenw8a8-2node-eplb
config_file_path: Qwen3-235B-W8A8-EPLB.yaml
size: 2
uses: ./.github/workflows/_e2e_nightly_multi_node.yaml
with:
soc_version: a3
runner: linux-aarch64-a3-0
image: 'swr.cn-southwest-2.myhuaweicloud.com/base_image/ascend-ci/vllm-ascend:nightly-a3'
replicas: 1
size: ${{ matrix.test_config.size }}
config_file_path: ${{ matrix.test_config.config_file_path }}
secrets:
KUBECONFIG_B64: ${{ secrets.KUBECONFIG_B64 }}
```
上面的矩阵定义了添加一个多机用例所需的所有参数。值得注意的参数(如果您正在添加一个新用例)是size和yaml配置文件的路径。前者定义了您的用例所需的节点数量,后者定义了您在步骤2中完成的配置文件的路径。
本地运行多节点测试#
1. Use kubernetes#
本节假设您本地已经有一个Kubernetes NPU集群环境。然后您可以轻松地一键启动我们的测试。
步骤 1. 安装LWS CRD资源
步骤 2. 按需部署以下yaml文件
lws.yamlapiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: test-server namespace: vllm-project spec: replicas: 1 leaderWorkerTemplate: size: 2 restartPolicy: None leaderTemplate: metadata: labels: role: leader spec: containers: - name: vllm-leader imagePullPolicy: Always image: swr.cn-southwest-2.myhuaweicloud.com/base_image/ascend-ci/vllm-ascend:nightly-a3 env: - name: CONFIG_YAML_PATH value: DeepSeek-V3.yaml - name: WORKSPACE value: "/vllm-workspace" - name: FAIL_TAG value: FAIL_TAG command: - sh - -c - | bash /vllm-workspace/vllm-ascend/tests/e2e/nightly/multi_node/scripts/run.sh resources: limits: huawei.com/ascend-1980: 16 memory: 512Gi ephemeral-storage: 100Gi requests: huawei.com/ascend-1980: 16 memory: 512Gi ephemeral-storage: 100Gi cpu: 125 ports: - containerPort: 8080 # readinessProbe: # tcpSocket: # port: 8080 # initialDelaySeconds: 15 # periodSeconds: 10 volumeMounts: - mountPath: /root/.cache name: shared-volume - mountPath: /usr/local/Ascend/driver/tools name: driver-tools - mountPath: /dev/shm name: dshm volumes: - name: dshm emptyDir: medium: Memory sizeLimit: 15Gi - name: shared-volume persistentVolumeClaim: claimName: nv-action-vllm-benchmarks-v2 - name: driver-tools hostPath: path: /usr/local/Ascend/driver/tools workerTemplate: spec: containers: - name: vllm-worker imagePullPolicy: Always image: swr.cn-southwest-2.myhuaweicloud.com/base_image/ascend-ci/vllm-ascend:nightly-a3 env: - name: CONFIG_YAML_PATH value: DeepSeek-V3.yaml - name: WORKSPACE value: "/vllm-workspace" - name: FAIL_TAG value: FAIL_TAG command: - sh - -c - | bash /vllm-workspace/vllm-ascend/tests/e2e/nightly/multi_node/scripts/run.sh resources: limits: huawei.com/ascend-1980: 16 memory: 512Gi ephemeral-storage: 100Gi requests: huawei.com/ascend-1980: 16 ephemeral-storage: 100Gi cpu: 125 volumeMounts: - mountPath: /root/.cache name: shared-volume - mountPath: /usr/local/Ascend/driver/tools name: driver-tools - mountPath: /dev/shm name: dshm volumes: - name: dshm emptyDir: medium: Memory sizeLimit: 15Gi - name: shared-volume persistentVolumeClaim: claimName: nv-action-vllm-benchmarks-v2 - name: driver-tools hostPath: path: /usr/local/Ascend/driver/tools --- apiVersion: v1 kind: Service metadata: name: vllm-leader namespace: vllm-project spec: ports: - name: http port: 8080 protocol: TCP targetPort: 8080 selector: leaderworkerset.sigs.k8s.io/name: vllm role: leader type: ClusterIP
kubectl apply -f lws.yaml
验证Pod的状态:
kubectl get pods -n vllm-project
应该会得到类似这样的输出:
NAME READY STATUS RESTARTS AGE vllm-0 1/1 Running 0 2s vllm-0-1 1/1 Running 0 2s
验证分布式推理是否正常工作:
kubectl logs -f vllm-0 -n vllm-project
应该会得到类似这样的结果:
INFO 12-30 11:00:57 [__init__.py:43] Available plugins for group vllm.platform_plugins: INFO 12-30 11:00:57 [__init__.py:45] - ascend -> vllm_ascend:register INFO 12-30 11:00:57 [__init__.py:48] All plugins in this group will be loaded. Set `VLLM_PLUGINS` to control which plugins to load. INFO 12-30 11:00:57 [__init__.py:217] Platform plugin ascend is activated INFO 12-30 11:00:57 [importing.py:68] Triton not installed or not compatible; certain GPU-related functions will not be available. ================================================================================================== test session starts =================================================================================================== platform linux -- Python 3.11.13, pytest-8.4.2, pluggy-1.6.0 -- /usr/local/python3.11.13/bin/python3 cachedir: .pytest_cache rootdir: /vllm-workspace/vllm-ascend configfile: pyproject.toml plugins: cov-7.0.0, asyncio-1.3.0, mock-3.15.1, anyio-4.12.0 asyncio: mode=Mode.STRICT, debug=False, asyncio_default_fixture_loop_scope=None, asyncio_default_test_loop_scope=function collected 1 item tests/e2e/nightly/multi_node/scripts/test_multi_node.py::test_multi_node [2025-12-30 11:01:01] INFO multi_node_config.py:294: Loading config yaml: tests/e2e/nightly/multi_node/config/DeepSeek-V3.yaml [2025-12-30 11:01:01] INFO multi_node_config.py:348: Resolving cluster IPs via DNS... [2025-12-30 11:01:01] INFO multi_node_config.py:212: Node 0 envs: {'VLLM_USE_MODELSCOPE': 'True', 'OMP_PROC_BIND': 'False', 'OMP_NUM_THREADS': '100', 'HCCL_BUFFSIZE': '1024', 'SERVER_PORT': '8080', 'NUMEXPR_MAX_THREADS': '128', 'DISAGGREGATED_PREFILL_PROXY_SCRIPT': 'examples/disaggregated_prefill_v1/load_balance_proxy_server_example.py', 'HCCL_IF_IP': '10.0.0.102', 'HCCL_SOCKET_IFNAME': 'eth0', 'GLOO_SOCKET_IFNAME': 'eth0', 'TP_SOCKET_IFNAME': 'eth0', 'LOCAL_IP': '10.0.0.102', 'NIC_NAME': 'eth0', 'MASTER_IP': '10.0.0.102'} [2025-12-30 11:01:01] INFO multi_node_config.py:159: Launching proxy: python examples/disaggregated_prefill_v1/load_balance_proxy_server_example.py --host 10.0.0.102 --port 6000 --prefiller-hosts 10.0.0.102 --prefiller-ports 8080 --decoder-hosts 10.0.0.138 --decoder-ports 8080 [2025-12-30 11:01:01] INFO conftest.py:107: Starting server with command: vllm serve vllm-ascend/DeepSeek-V3-W8A8 --host 0.0.0.0 --port 8080 --data-parallel-size 2 --data-parallel-size-local 2 --tensor-parallel-size 8 --seed 1024 --enforce-eager --enable-expert-parallel --max-num-seqs 16 --max-model-len 8192 --max-num-batched-tokens 8192 --quantization ascend --trust-remote-code --no-enable-prefix-caching --gpu-memory-utilization 0.9 --kv-transfer-config {"kv_connector": "MooncakeConnectorV1", "kv_role": "kv_producer", "kv_port": "30000", "engine_id": "0", "kv_connector_extra_config": { "prefill": { "dp_size": 2, "tp_size": 8 }, "decode": { "dp_size": 2, "tp_size": 8 } } }
2. Test without kubernetes#
由于我们的脚本对Kubernetes友好,如果您没有Kubernetes环境,则需要主动传入一些集群信息。
步骤 1. 向配置YAML文件添加cluster_hosts
在每个集群主机上进行修改,就像DeepSeek-V3.yaml那样,在配置项
num_nodes之后添加,例如:cluster_hosts: ["xxx.xxx.xxx.188", "xxx.xxx.xxx.212"]步骤 2. 安装开发环境
在每个集群主机上安装vllm-ascend开发包
cd /vllm-workspace/vllm-ascend python3 -m pip install -r requirements-dev.txt
在cluster_hosts中的第一个主机(主节点)上安装AISBench
export AIS_BENCH_TAG="v3.0-20250930-master" export AIS_BENCH_URL="https://gitee.com/aisbench/benchmark.git" export BENCHMARK_HOME=/vllm-workspace/benchmark git clone -b ${AIS_BENCH_TAG} --depth 1 ${AIS_BENCH_URL} $BENCHMARK_HOME cd $BENCHMARK_HOME pip install -e . -r requirements/api.txt -r requirements/extra.txt
步骤 3. 本地运行测试
在每个节点上分别运行脚本
export WORKSPACE=/vllm-workspace # Change it to your path locally export CONFIG_YAML_PATH="DeepSeek-V3.yaml" # Replace with the config case you added cd $WORKSPACE/vllm-ascend bash tests/e2e/nightly/multi_node/scripts/run.sh