RFork 指南#
本指南介绍如何在 vLLM Ascend 中使用 RFork 作为模型加载器插件。
概述#
RFork 是 vLLM Ascend 的一种热启动权重加载路径。新实例无需总是从存储中读取模型权重,而是可以从外部规划器请求一个兼容的 种子 实例,然后通过 YuanRong TransferEngine 直接从该种子拉取权重。
当前实现中,RFork 的加载流程如下:
vLLM 以
--load-format rfork参数启动。RFork 根据模型标识和部署拓扑构建一个 种子键。
RFork 向规划器请求一个与该键匹配的可用种子。
如果返回了一个种子,新实例将在其本地 NPU 上初始化模型结构,注册本地权重内存,从种子获取远程传输引擎的元数据,并执行批量权重传输到本地参数缓冲区。
如果没有可用种子,或任何步骤失败,RFork 将进行清理并回退到默认加载器。
实例完成加载后,会启动一个本地种子服务,并定期向规划器发送心跳,以便后续实例可以复用该实例。
流程图#
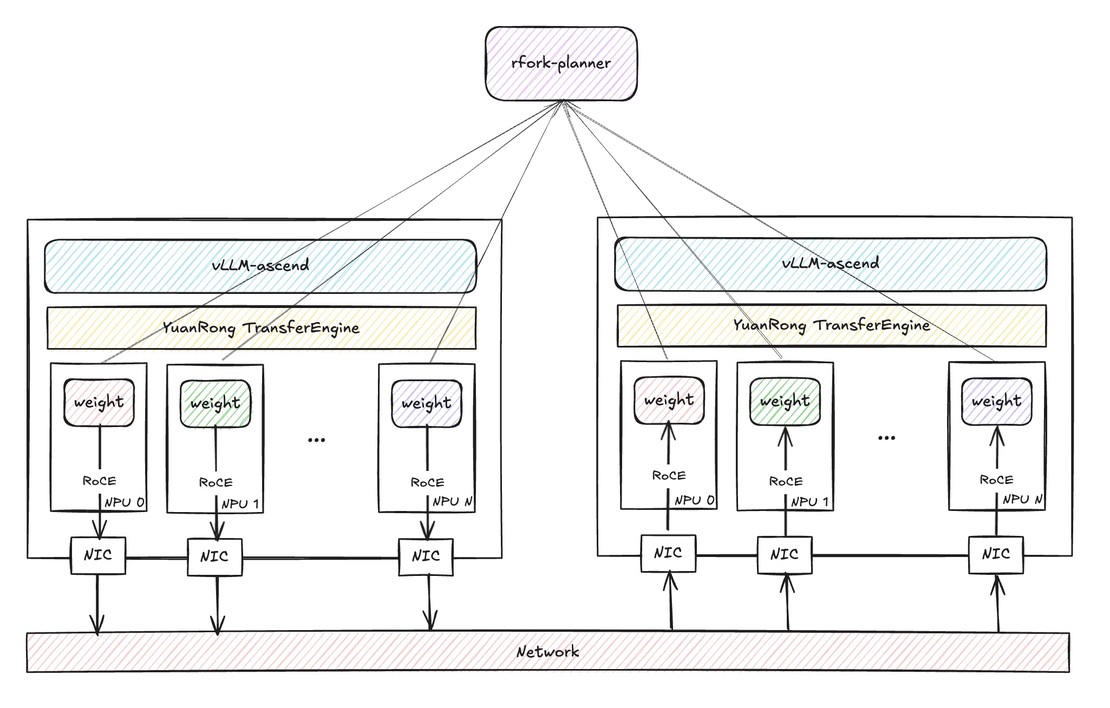
应用场景#
首次成功加载后的横向扩展:第一个实例可能仍需从存储加载,但后续具有相同部署标识的实例可以将其作为种子复用,从而缩短启动时间。
弹性服务集群:由于 RFork 会向规划器请求可用种子,因此它适用于实例动态创建和回收的集群。
拓扑敏感的部署:RFork 将
kv_role、node_rank、tp_rank以及可选的draft角色编码到种子键中,因此只有拓扑兼容的实例才会被匹配在一起。
使用方法#
要启用 RFork,请传递 --load-format rfork 参数,并通过 --model-loader-extra-config 以 JSON 字符串的形式提供 RFork 设置。
RFork 先决条件#
在每个 RFork 实例上安装运行时依赖
YuanRong TransferEngine。运行一个实现了 RFork 种子协议的规划器服务。在
rfork_planner.py提供了一个简单的模拟规划器脚本。
配置字段#
字段名 |
类型 |
描述 |
允许值 / 备注 |
|---|---|---|---|
model_url |
字符串 |
用于构建 RFork 种子键的逻辑模型标识符。 |
RFork 传输所必需。应共享种子的实例必须使用相同的值。 |
model_deploy_strategy_name |
字符串 |
部署策略标识符,与 |
RFork 传输所必需。应共享种子的实例必须使用相同的值。 |
rfork_scheduler_url |
字符串 |
用于种子分配、释放和心跳的规划器服务的基础 URL。 |
基于规划器的匹配所必需。示例: |
rfork_seed_timeout_sec |
数字 |
启动后等待本地种子 HTTP 服务变为健康状态的超时时间。 |
可选。默认值: |
rfork_seed_key_separator |
字符串 |
构建 RFork 种子键字符串时使用的分隔符。 |
可选。默认值: |
RFork 如何匹配种子#
RFork 不仅通过 model_url 来匹配实例。本地种子键由以下部分组成:
model_urlmodel_deploy_strategy_name从
kv_transfer_config.kv_role或kv_both派生的解耦模式node_ranktp_rank当工作器作为草稿模型运行时,可选的
draft后缀
这意味着两个实例必须在模型标识和部署拓扑上都达成一致,规划器才会将它们视为可互换的种子。
示例命令与占位符#
Replace parts in
<...>before running.
1.安装 YuanRong TransferEngine#
pip install openyuanrong-transfer-engine
2.启动规划器#
在 rfork_planner.py 提供了一个简单的规划器实现。
python rfork_planner.py \
--host 0.0.0.0 \
--port <planner_port>
3.启动 vLLM 实例#
对于同一部署中的第一个实例和后续实例,使用相同的 RFork 启动命令。
对于第一个实例,规划器通常还没有兼容的种子,因此 RFork 会回退到默认加载器。加载完成后,该实例会启动其本地种子服务,并向规划器报告自身。
对于后续实例,如果规划器能分配一个兼容的种子,RFork 将尝试从现有的种子实例传输权重,然后再回退到默认加载器。
export RFORK_CONFIG='{
"model_url": "<model_url>",
"model_deploy_strategy_name": "<deploy_strategy>",
"rfork_scheduler_url": "http://<planner_ip>:<planner_port>"
}'
vllm serve <model_path> \
--tensor-parallel-size 1 \
--served-model-name <served_model_name> \
--port <port> \
--load-format rfork \
--model-loader-extra-config "${RFORK_CONFIG}"
占位符说明#
<model_path>:传递给vllm serve的模型路径或模型标识符。<served_model_name>:vLLM 暴露的服务名称。<planner_ip>:RFork 规划器的 IP 地址或主机名。<planner_port>:RFork 规划器的监听端口。<model_url>:用于构建 RFork 种子键的稳定模型标识字符串。<deploy_strategy>:用于构建 RFork 种子键的稳定部署策略名称。<port>:正在启动的 vLLM 实例的服务端口。
注意事项与限制#
RFork 在运行时需要
YuanRong TransferEngine。如果缺少该软件包,RFork 将无法初始化传输后端。如果使用 RFORK,每个工作进程都必须绑定一个监听端口。该端口是随机分配的。
示例
rfork_planner.py仅是一个简单的模拟实现。如果您需要更强大的调度、容量管理或生产级可用性行为,请基于 RFork 种子协议实现您自己的规划器。