层分片线性算子指南#
概述#
层分片线性算子 是一项为大语言模型推理设计的内存优化功能。它旨在解决由跨越多层的重复线性算子所引起的高内存压力,这些算子结构相同但权重不同。
与在每个设备上复制所有权重不同,层分片线性算子将此类算子的一个"系列"的权重分片到通信组内的NPU设备上:
第 i 层的线性权重 仅存储在设备
i % K上,其中K是组内的设备数量。其他设备在初始化期间持有一个轻量级的共享虚拟张量,并在前向传播期间通过异步广播按需获取真实权重。
如下图所示,这种设计使得广播能够触及权重:在当前层(例如MLA或MOE)进行计算时,系统在后台异步广播下一层的权重。由于MLA模块中的注意力计算是充分延迟受限的,o_proj的权重传输与计算完全重叠,使得从端到端推理的角度看,通信没有额外延迟。
这种方法保持了精确的计算语义,同时显著减少了NPU内存占用,这对于以下情况尤其关键:
极深的架构(例如,具有61层的DeepSeek-V3/R1);
使用 DSA-CP 或 FlashComm2 的模型,其中完整的
O(输出)投影矩阵必须驻留在每层的内存中;**注意力计算延迟完全覆盖(隐藏)**权重广播通信成本的场景。
流程图#
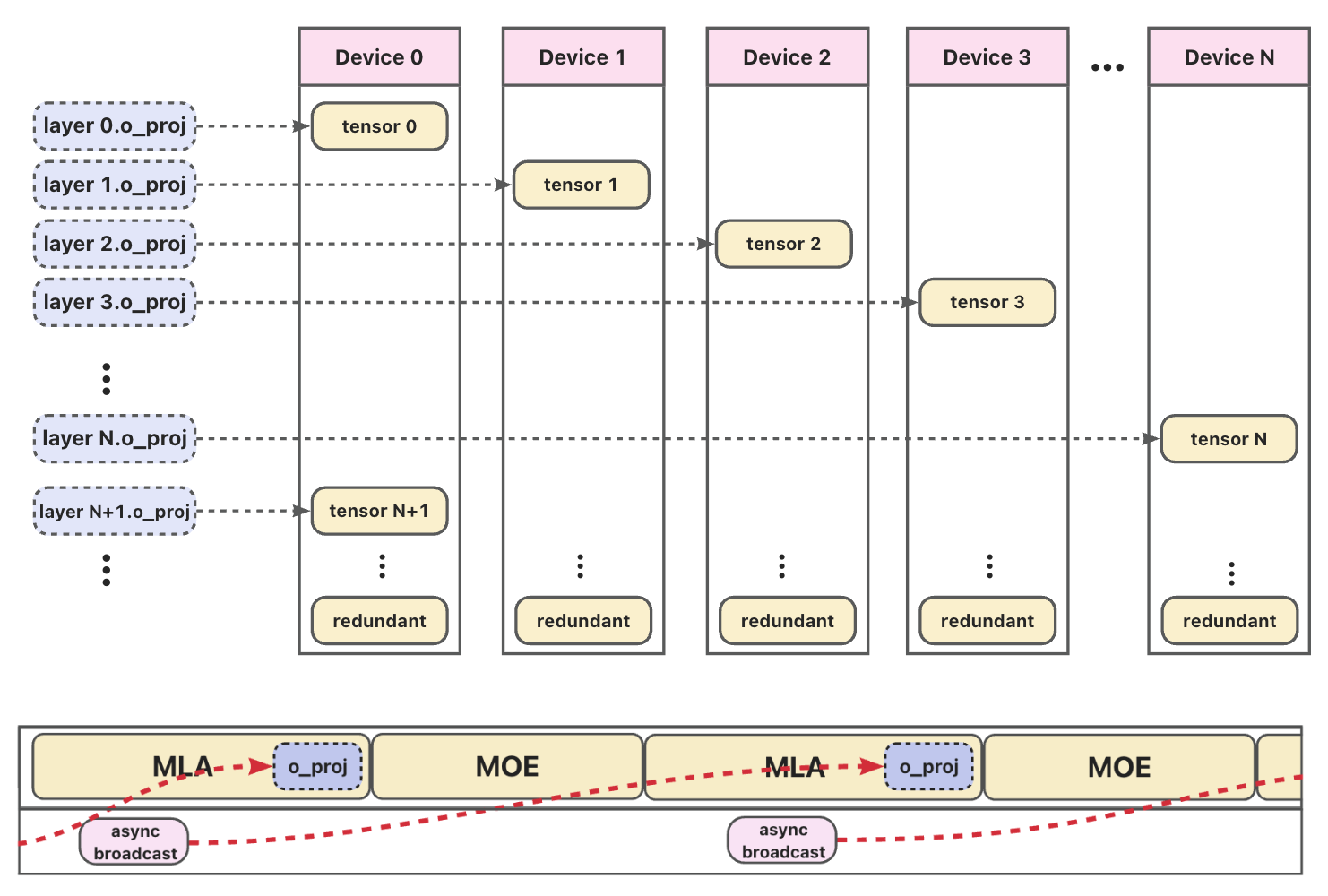
图. 层分片线性算子工作流程:权重按层分片到各设备(顶部),在前向执行期间(底部),异步广播预取下一层的权重,同时当前层进行计算——实现零开销的权重加载。
快速开始#
要启用层分片线性算子,请在启动推理作业时使用 --additional-config 参数指定目标线性层。例如,要对 o_proj 和 q_b_proj 层进行分片,请使用:
--additional-config '{
"layer_sharding": ["o_proj", "q_b_proj"]
}'
限制 在PD解耦部署中,层分片只能在
kv_role="kv_producer"的 P节点 上启用。不支持kv_role="kv_consumer"和kv_role="kv_both"。
支持场景#
此功能在以下情况下能带来最大收益:
启用FlashComm2#
当使用 FlashComm2 时,完整的输出投影(o_proj)矩阵必须驻留在每层的内存中。层分片通过将这些权重分布到各设备上,显著降低了内存压力。
配置示例:
export VLLM_ASCEND_FLASHCOMM2_PARALLEL_SIZE=1
vllm serve \
--model DeepSeek-V3/R1 \
--additional-config '{
"layer_sharding": ["o_proj"]
}'
启用DSA-CP#
使用 DSA-CP 时,q_b_proj 和 o_proj 层都需要每层存储大型权重矩阵。将这些层分片到多个NPU上有助于将极深的模型(例如,61层架构)装入有限的设备内存中。
在PD解耦部署中,此模式仅在 kv_role="kv_producer" 的 P节点 上受支持。
配置示例:
export VLLM_ASCEND_ENABLE_FLASHCOMM1=1
vllm serve \
--model DeepSeek-V3.2 \
--additional-config '{
"layer_sharding": ["q_b_proj", "o_proj"]
}'