Netloader 指南#
本指南介绍如何使用 Netloader 作为权重加载器插件,以在 vLLM Ascend 中实现加速。
概述#
Netloader 利用 NPU 卡之间的高带宽点对点 (P2P) 传输来加载模型权重。它通过插件实现(使用 vLLM 0.10 中添加的 register_model_loader API)。工作流程如下:
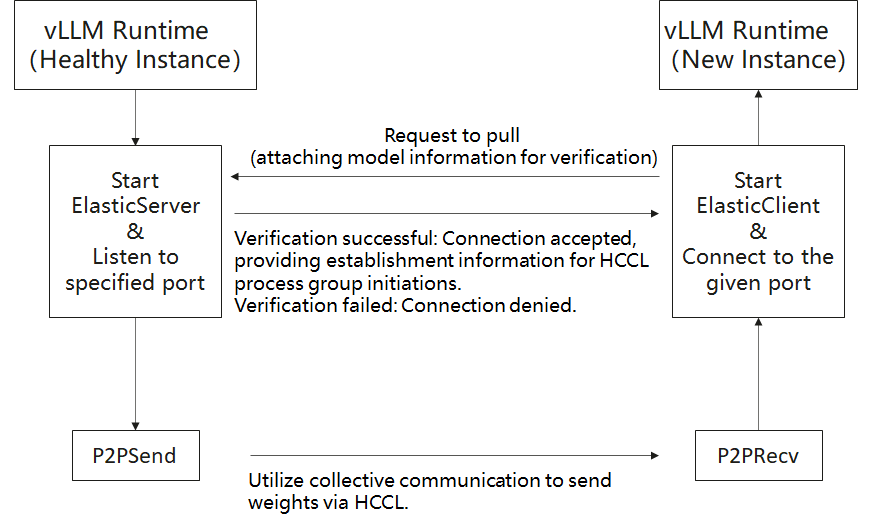
服务器 预加载模型。
新的 客户端 实例请求权重传输。
在验证模型和分区匹配后,客户端使用 HCCL 集合通信 (send/recv) 按照模型中存储的相同顺序接收权重。
服务器通过子线程以及 vLLM 中的 stateless_init_torch_distributed_process_group 与常规推理任务并行运行。因此,客户端接管权重初始化,无需从存储加载。
流程图#
时序图#
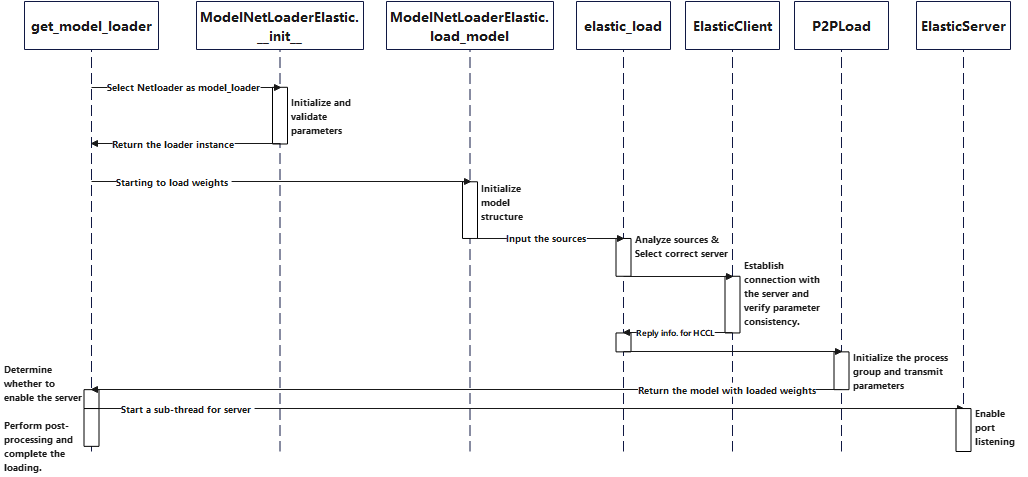
应用场景#
减少启动延迟:通过重用已加载的权重并在 NPU 卡之间直接传输,Netloader 相比传统的远程/本地拉取策略,缩短了模型加载时间。
减轻网络和存储负载:避免从远程仓库重复下载权重文件,从而减轻中心存储和网络流量的压力。
提高资源利用率并降低成本:更快的加载速度减少了对备用计算节点的依赖;资源可以更灵活地伸缩。
增强业务连续性和高可用性:在故障恢复时,新实例可以快速接管而无需长时间停机,从而提高系统可靠性和用户体验。
使用方法#
要启用 Netloader,请传递 --load-format=netloader 并通过 --model-loader-extra-config(作为 JSON 字符串)提供配置。以下是支持的配置字段:
字段名 |
类型 |
描述 |
允许值 / 备注 |
|---|---|---|---|
SOURCE |
列表 |
权重数据源。每个条目是一个包含 |
一个对象列表,其键为 |
MODEL |
字符串 |
模型名称,用于验证客户端和服务器之间的一致性。 |
如果未指定,则默认为 |
LISTEN_PORT |
整数 |
服务器监听器的基础端口。 |
实际端口 = |
INT8_CACHE |
字符串 |
处理量化模型中 int8 参数的行为。 |
取值为 |
INT8_CACHE_NAME |
列表 |
应用 |
默认值: |
OUTPUT_PREFIX |
字符串 |
在服务器模式下,用于写入每个 rank 监听器地址/端口文件的前缀。 |
如果设置,每个 rank 将写入 |
CONFIG_FILE |
字符串 |
指定上述配置的 JSON 文件路径。 |
如果提供,此文件内的 SOURCE 具有 最高优先级(覆盖其他配置中的 SOURCE)。 |
示例命令与占位符#
运行前替换
`<...>`中的部分。
服务器#
VLLM_SLEEP_WHEN_IDLE=1 vllm serve <model_file> \
--tensor-parallel-size 1 \
--served-model-name <model_name> \
--enforce-eager \
--port <port> \
--load-format netloader
客户端#
export NETLOADER_CONFIG='{"SOURCE":[{"device_id":0, "sources": ["<server_IP>:<server_Port>"]}]}'
VLLM_SLEEP_WHEN_IDLE=1 ASCEND_RT_VISIBLE_DEVICES=<device_id_diff_from_server> \
vllm serve <model_file> \
--tensor-parallel-size 1 \
--served-model-name <model_name> \
--enforce-eager \
--port <client_port> \
--load-format netloader \
--model-loader-extra-config="${NETLOADER_CONFIG}"
占位符说明#
<model_file>:模型文件路径<model_name>:模型名称(服务器和客户端之间必须匹配)<port>:服务器上的基础监听端口<server_IP>+<server_Port>:Netloader 服务器的 IP 和端口(来自服务器日志)<device_id_diff_from_server>:客户端设备 ID(必须与服务器的不同)<client_port>:客户端监听的端口
启动后,您可以通过发送 temperature = 0 的推理请求并比较输出来测试一致性。
注意事项与限制#
如果使用 Netloader,每个工作进程 都必须绑定一个监听端口。该端口可以是用户指定的,也可以是随机分配的。如果是用户指定的,请确保其可用。
Netloader 需要额外的片上内存来建立 HCCL 连接(即
HCCL_BUFFERSIZE,默认约 200 MB)。用户应预留足够的容量(例如通过--gpu-memory-utilization)。建议设置
VLLM_SLEEP_WHEN_IDLE=1以缓解不稳定或缓慢的连接/传输。相关信息:vLLM Issue #16660, vLLM PR #16226。